令和6年7月5日、総務省から「令和6年版情報通信白書」が公表されました。
今年の情報通信白書は「令和6年能登半島地震における情報通信の状況」と、AIやメタバース、ロボティクスに関する「進化するデジタルテクノロジーとの共生」の2つの特集となっています。
どれも貴重な情報ですが、AIに関心がある身としてはAI関連の調査資料が非常に興味深いものでした。
そこで本記事では、総務省が公表した「令和6年版情報通信白書」のなかから、AI関連の情報だけ抽出してまとめました。
AI関連の調査内容を活用するご予定がある方は、本記事をブックマークしておくことをおすすめします。
ご自身で一つずつもとの資料を確認したい場合は、総務省の「令和6年版情報通信白書」をご確認ください。

第5章 第1節:国民・企業による利用状況
該当資料:第1 節 国民・企業における利用状況
日本、米国、中国、ドイツ、英国を対象に実施されたアンケート調査に関する資料です。
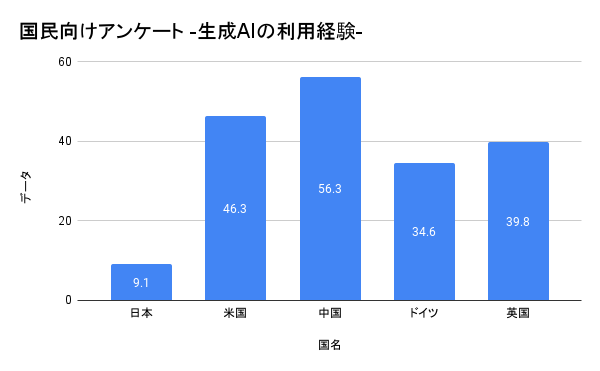
国民向けアンケート
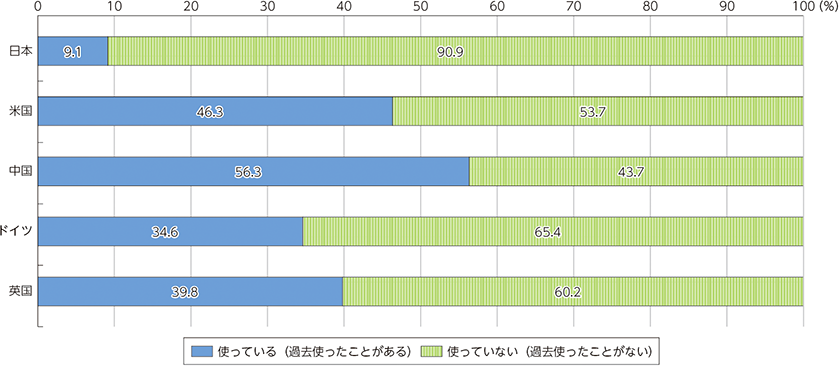
日本で “生成AIを“使っている”(「過去使ったことがある」も含む)と回答した割合は 9.1%であり、他国と比べて低い結果となりました。
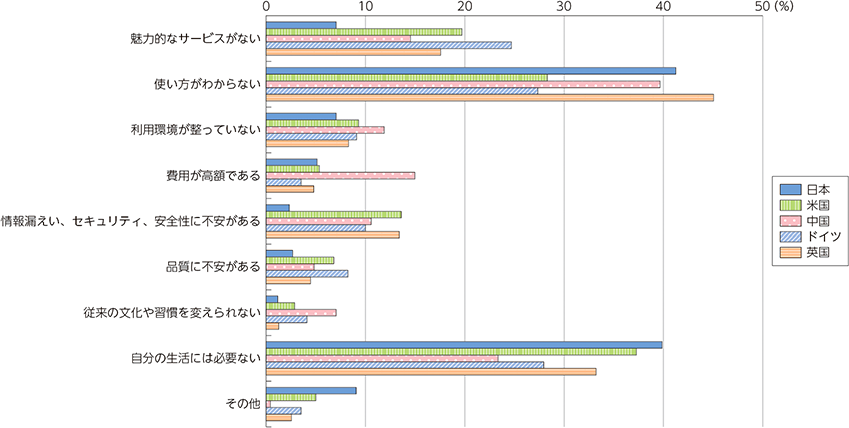
続いて、使っていない理由の調査では、どの国でも「使い方がわからない」「自分の生活には必要ない」といった回答が多く、国による違いはなさそうです。
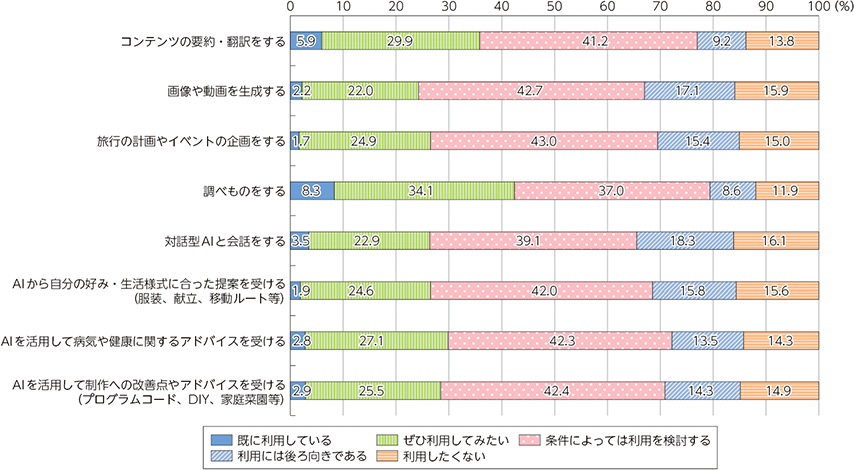
一方で生成AIを利用したいかどうかその意向の調査では、「ぜひ利用したい」「条件によっては利用を検討する」という回答が6〜7割。潜在的なニーズは高いと言えそうです。
企業向けアンケート
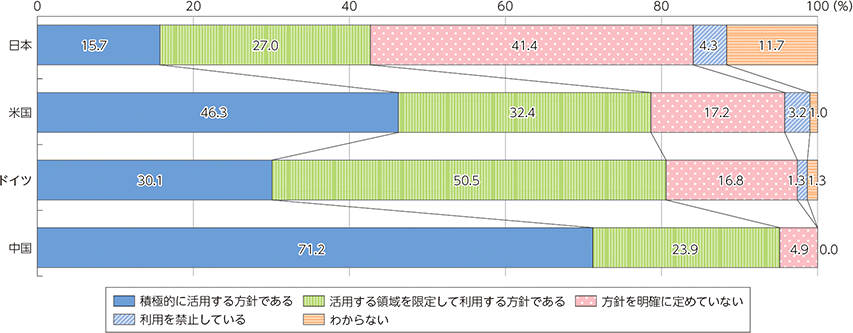
生成AIの活用方針に関するアンケートでは、“活用する方針を定めている”(「積極的に活用する方針である」、「活用する領域を限定して利用する方針である」の合計)と回答した割合は42.7%でした。
米国、ドイツ、中国は“活用する方針を定めている”が約8割。比較すると日本は約半数という結果になりました。
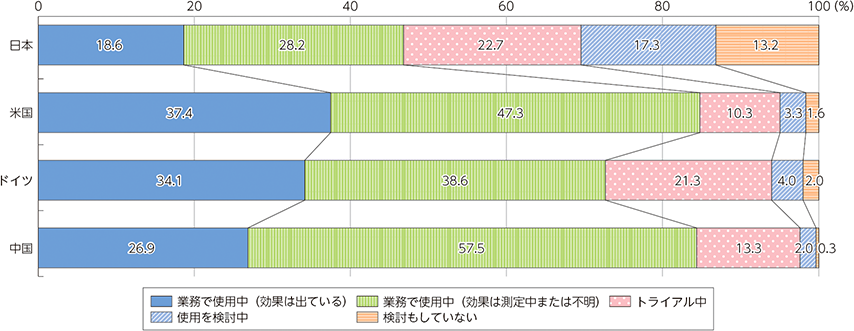
メールや議事録、資料策などAI活用が想定されるシーンでの活用状況の調査では、生成AIを「業務で使用中」と回答した割合は、日本が46.8%。
「トライアル中」を含めると、米国、ドイツ、中国の企業は90%程度が使用。顧客対応を含む多くの領域で積極的な利活用が始まっている。
日本企業は慎重な導入が進められており、他国と比べて導入の割合が低い。
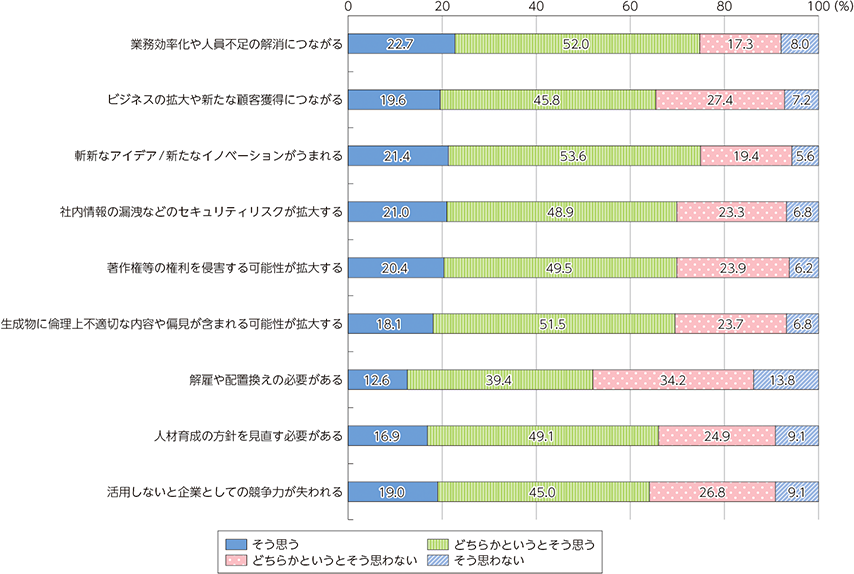
生成AI活用による効果・影響については、約75%が“業務効率化や人員不足の解消につながると思う”(「そう思う」と「どちらかというとそう思う」の合計)と回答。
一方、“社内情報の漏洩などのセキュリティリスクが拡大すると思う”、“著作権等の権利を侵害する可能
性があると思う”と回答した企業も約7割あり、生成AIのリスクを懸念していることがうかがえた。
第5章 第2節:活用の現状・新たな潮流
該当資料:第2 節 活用の現状・新たな潮流
先ほどはアンケート調査だったのに対し、こちらの資料は具体的な企業名や団体名を挙げて事例を紹介しています。
企業・公共団体等における生成AI導入動向
NTTデータ
NTTデータは、2019年5月に「NTTデータグループAI指針」を策定、同社のAIガバナンスの在り方を検討するため2021年4月に社外の有識者からなる「AIアドバイザリーボード」を設置するなど、従来から公平かつ健全なAI活用による価値創造と持続的な社会の発展に向けた活動を実施してきたが、さらに、ビジネスに影響するAIの不適切な利用による事業リスクに適切に対処し、お客さまに安全なAIシステムの提供を実現するための組織として、AIガバナンス室を2023年4月に設置した。同年7月からはNTTデータの国内事業でAIやデータ活用が関わる案件全てを対象に、チェックリストを使いリスク管理をする運用を始めた。
引用元:第2 節 活用の現状・新たな潮流
要するに、AIは価値を生み出すのと同時に重大なリスクも孕んでいるため、そうしたリスクから企業を守るため、リスクを検知するルールや体制の整備をサポートする「AIガバナンス室」を設立したのです。

AIガバナンスとは、AIシステムの開発と利用において、倫理的・法的・社会的な側面を考慮し、リスクを管理しながら適切に活用していくための枠組みのことです。具体的には、AIの公平性、説明可能性、安全性、プライバシー保護などの原則を定め、ポリシーや体制を整備することで、AIの恩恵を最大化しつつ、負の影響を最小化することを目指します。
横須賀市
横須賀市は、庁内における取組として、2023年6月のChatGPTの庁内への一斉導入から始め、職員の活用促進や正しい利用方法の発信のための「ChatGPT通信」創刊、職員向けの独自研修プログラム、職員を対象としたChatGPT活用コンテスト、外部からのアドバイスを受ける目的での「AI戦略アドバイザー」の設置等の取組を行っている。
引用元:第2 節 活用の現状・新たな潮流
また、庁内で培った知見やノウハウを他の自治体にも共有を行っており、2023年8月より取組内容に関する問合せに回答する他自治体向けの問合せボットの運用を開始、さらに同月、先行して生成AIを活用する自治体のノウハウや試行錯誤の過程を発信するポータルサイト「自治体AI活用マガジン」を立ち上げた。全国の自治体や企業向けに2日間にわたる研修プログラム「横須賀生成AI合宿」の開催も行った。
関連記事を調べてみたところ、庁内の業務サポートとしてChatGPTを使ったチャットボットを設置。そのうえで職員向けに活用方法をマガジン形式で紹介する「ChatGPT通信」を創刊。
その結果8割以上の職員からAI活用に対するポジティブな意見がもらえ、AI活用リテラシーも向上したとのこと。

各領域・業界における活用動向
サイバーエージェント

メディアやゲーム、音楽などのコンテンツ制作分野においては、コンテンツそのものの制作や制作における補助として生成AIを利用することで、労働力不足の中で、クリエイターがより効率的にコンテンツを作成することが可能となる。
引用元:第2 節 活用の現状・新たな潮流
サイバーエージェントでは、2023年5月に、AIを活用した広告クリエイティブ制作を実現する自社開発の「極予測AI」に、ChatGPTを活用したキャッチコピー文案自動生成機能を実装した。
これにより、広告画像の内容を考慮しながら、従来よりも詳細なターゲットに合わせて広告コピーを作り分けることができるようになった。また、2023年12月にはAIを活用した商品画像自動生成機能を開発し、あらゆるシチュエーションと商品画像の組合せを大量に自動生成することが可能になった。さらに生成した商品画像と効果予測AIを活用し、予測を行いながらより効果の高い商品画像の提供を実現するとしている。
広告のターゲティング精度を高めるツールに生成AIを導入し、広告コピーや画像をAIが作成できるような仕組みを作ったとのこと。また、広告コピー生成に使用するAIはGPTだけでなく、自社で開発したAIと組み合わせているそうです。


顧客接点における活用(アフラック生命保険)
顧客サービス分野においては、利便性向上のための利用者向けサポートと、利用者に対峙するスタッフの業務効率向上のための支援や教育、サービス自体の健全な利用のために不正検知を行うといった活用方法がある。顧客接点における満足度向上の側面や、さらに応対する個人の知識やセンスを問わず一定の品質を保てるようになることが見込まれている。特に離職率が高く人手不足になりがちなコンタクトセンター等の分野でオペレーターに適切な知識を伝え業務の後方支援を行うことによる労働力不足解消の可能性を秘めている。
引用元:第2 節 活用の現状・新たな潮流
例えば、アフラック生命保険では、保険代理店向けサービスとして、AIのアバターを相手とするロールプレイング研修「募集人教育AI」を開発した。営業担当者が保険セールスの会話の中で挙げるべきキーワードを盛り込んでいるかどうかなどを、音声認識をはじめとする技術を用いて分析して評価する仕組みであり、将来的には、実際の顧客の情報を取り込んで、営業活動を疑似体験できるところまで機能の発展を見込む。
2022年12月の時点で、AIを使った保険営業のロールプレイシステムを構築。システム導入によって営業成績が30%向上したとのこと。

情報サービス(NTTデータ)
ソフトウェア開発等を行う情報サービス分野において、生成AIは要件定義、仕様生成、プログラミング、テストなどのあらゆる工程での活用が見込まれている。生成AIによる生産性向上により、エンジニアの需要が高まる中で人手不足解消の手助けとなる可能性を秘めている。特に、SIerにおいては、COBOL資産のモダナイゼーションへの活用も目論んでいる。
引用元:第2 節 活用の現状・新たな潮流
NTTデータでは、要件定義からテスト工程までシステム開発の全フェーズで生成AIの適用の推進を行っている。海外を中心にPoCだけでなく商用利用での適用実績があり、製造工程において7割の合理化によって工期を短縮した例や、生産性を約3倍向上させた例もある。2023年10月には日本におけるマイグレーションのPoCを始めている。製造工程やテスト工程における利用が現時点でメインとなっており、製造工程においては新規ソースコードの生成や古いプログラム言語を新しいプログラム言語に書き換えるモダナイゼーションに活用する。テスト工程においては過去の設計書や試験目標等のデータを生成AIに読み込ませ、テスト項目を自動抽出できるようにするとしている。
非エンジニアの方向けに説明すると、NTTデータ社はエンジニアの業務のあらゆる工程でAIを活用。特に古いシステムを最新の技術に書き換える業務での活用を進めているとのこと。
関連記事によれば、生成AIの導入によって約3倍の生産性が向上した例もあるそうです。

建設分野における活用(大林組)
建設分野においては、デザイン案の短時間での作成や設計において測量データ、設計図書や仕様書などの過去データを参照して建設における専門的な知識を扱い回答する等の場面で生成AI活用が見込まれている。膨大な時間外労働、職人の高齢化による大量離職、資材価格の高騰などにより業界全体が圧迫されている中、書類作成などの効率化、ベテランの経験の活用、公開されている情報と社内の専門的な知見の結びつけにおいて効果が期待されている。
引用元:第2 節 活用の現状・新たな潮流
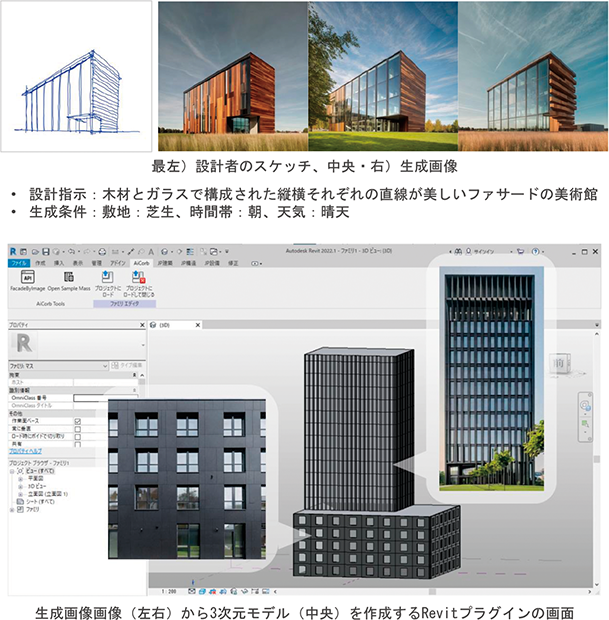
大林組は、2022年3月に建築設計の初期段階におけるスケッチや3Dモデルからさまざまな建物の外観デザインを提案できるAI技術「AiCorb(アイコルブ)」を米SRI Internationalと共同で開発したと発表し、2023年7月より社内運用を開始した。手描きのスケッチと建物をイメージした文章を基に、様々なファサード(建物の正面外観)のデザイン案を短時間で出力し、生成したデザインを基に3次元(3D)モデルを作成する。
2022年3月、生成AIブームまえの事例です。手書きでスケッチした建築物の外観とその説明からデザインを考案するAI、さらにそのデザインを3Dモデル化するAI、2つのAIを組み合わせています。

材料分野における活用(Preferred Networks、ENEOS)
材料開発の分野においては、AIの機械学習や統計手法を使用して大量の実験・計算データを解析、モデルを構築し新材料開発につなげるデータ駆動型アプローチ(Materials informatics(マテリアルズ・インフォマティクス))が発展してきた。生成AIについても、敵対的生成ネットワーク(GAN)や変分自己符号化器(VAE)といった生成モデルを活用し、既存の材料データセットを学習し、理論上の新材料を設計することで新しい材料の分子構造や結晶構造を自動的に生成することが可能になるほか、生成AIを使用して実データに基づいた仮想データを生成し、実験データセットを拡張することで、モデル学習の改善につながる。
引用元:第2 節 活用の現状・新たな潮流
2021年7月に、Preferred NetworksとENEOSはPreferred Computational Chemistry
(PFCC)を共同で設立し、ディープラーニング(深層学習)を活用した汎用原子レベルシミュレーター(Matlantis(マトランティス))をクラウドサービスとして提供開始した。生成AIを活用した原子シミュレーションによって、原子レベルでの有望な材料の特性把握や新材料開発や材料探索を支援する。従来のシミュレーションと比べて精度を保ったまま10万倍から数千万倍高速化し、高性能なコンピュータを用いて数時間~数か月かかった原子レベルの物理シミュレーションを、数秒単位で行うことが可能となったほか、55種類の元素をサポートし未知の分子や結晶など未知の材料に対してもシミュレーションできる汎用性を兼ね備え、国内外で80以上の大学・企業に利用されている(2024年1月時点)。
素材開発は、素材を組み合わせを変えて新素材を開発する。生成AIに既存の素材の組み合わせをデータセットとして与え、新しい素材を開発する試み。新しい素材ができればそれがまたAIの学習データになるポジティブなサイクルになっている。
関連資料: マテリアルズ・インフォマティクスの発展 と今後の展望
公的領域における活用
教育(ベネッセ等)
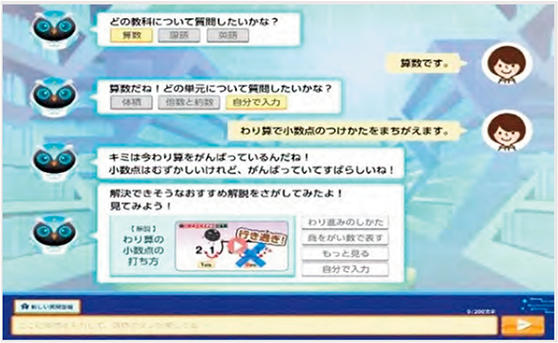
教育分野においては、学習者自身が生成AIと会話を行うことで個別にカスタマイズされた教材で自律的な学習、学習者の質問に回答するなどの学習支援、教材やテストの作成補助などの教師向けの支援等への活用が見込まれている。実際に学校に配置されている教師の数が、各都道府県・指定都市等の教育委員会において学校に配置することとしている教師の数を満たしておらず欠員が生じる状態である深刻な「教師不足」が続くこの分野において、生成AI活用を行うことで学習者にはいつでも気兼ねなく質問ができる環境や自律的な教育支援、教師の教材作成における稼働削減につながる可能性を秘めている。
引用元:第2 節 活用の現状・新たな潮流
文部科学省では、2023年7月に「初等中等教育段階における生成AIの利用に関する暫定的なガイドライン」を公表し、学校現場が生成AIの活用の適否を判断する際の参考となるよう一定の考え方をとりまとめている。また、同年、本ガイドラインに基づき、生成AIへの懸念に対して十分な対策を講じられる37自治体52校を生成AIパイロット校として指定し、学校現場における利用に関する成果・課題の検証を進めている。
他にも、ベネッセホールディングスは、「自由研究おたすけAI」、「AIしまじろう」、「チャレンジAI学習コーチ」等自社の教育サービスへの展開を行っている(図表Ⅰ-5-2-3)。2024年3月に提供開始された「チャレンジAI学習コーチ」は、「進研ゼミ」の学習や学校の宿題に取り組む中での疑問点をいつでもわかるまで質問できる、生成AIを活用した小・中学生向けのサービスである。
教育における生成AIの活用における課題の一つとされる「答えを直接聞いてしまう」との懸念に対し、「チャレンジAI学習コーチ」は、問題の答えを直接教えるのではなく、子どもたちの疑問に寄り添い、AIキャラクターと対話を通じて考え方や視点を広げるサポートをし、自ら答えにたどり着けるように開発されている。
学習者向けの活用例
- 個別にカスタマイズされた教材による自律的な学習
- 学習者の質問に回答するなどの学習支援
教師向けの活用例
- 教材やテストの作成補助
教師不足の解消に向けた可能性
- 学習者にはいつでも気兼ねなく質問ができる環境の提供
- 自律的な教育支援の実現
- 教師の教材作成における稼働削減


医療・介護における活用(シーディーアイ)
医療・介護分野において、生成AIは個々の利用者に合わせたケアプランの最適化や業務報告の自動化、利用者とのコミュニケーションの改善、研修や教育ツール等としての活用が見込まれており、利用者だけではなく職員に必要な専門知識を補う効果や業務効率化が期待される。高齢者人口の増加により需要が増し、生産年齢人口の急減に伴い労働力不足が課題となるこの分野においては、生成AIがより自然な言語で職員の業務上の相談相手となる可能性を秘めている。
引用元:第2 節 活用の現状・新たな潮流
シーディーアイは、2023年6月にAIを活用したケアマネジメント支援ツール「SOIN」とChatGPTとの連携を開始した。ケアマネジャーが既に入力している利用者の属性情報、疾患、身体状態などの情報に基づき、SOINサーバーがChatGPT向けのコマンドプロンプトを自動作成し、ChatGPTはパーソナライズされた支援内容をケアマネジャーに提供する。また、同社は2023年12月に「SOIN AI Chat」をリリースし、高齢者一人ひとりの個別状況を考慮した上で、ケアマネジャーの相談相手となる機能も追加している。
利用者向けの活用例
- 個々の利用者に合わせたケアプランの最適化
- 利用者とのコミュニケーションの改善
職員向けの活用例
- 業務報告の自動化
- 研修や教育ツールとしての活用
- 職員に必要な専門知識を補う効果
- 業務効率化
生成AIの可能性
- 高齢者人口の増加に伴う需要増加への対応
- 生産年齢人口の急減による労働力不足の課題解決
- より自然な言語で職員の業務上の相談相手となる



行政サービスにおける活用(議事録検索)
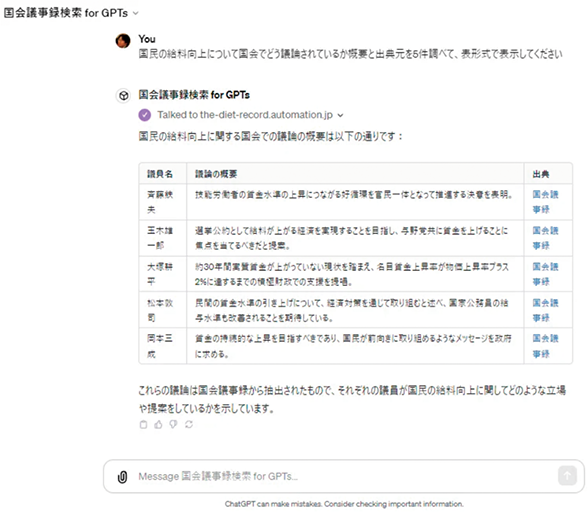
国会議事録検索 for GPTsを開発・リリースしました!」
行政サービスにおいては、情報収集や政策案の策定などの政策の検討、過去法案の収集や法案策定、(法案審議における)答弁作成などの一連の法制化事務、政策の周知や問合せ対応などの情報提供、様式の作成、チェックや判断、結果の交付などの執行、会議の実施などの事務における活用が見込まれている。
引用元:第2 節 活用の現状・新たな潮流
例えば、自動処理は、2023年11月に国会議事録検索 for GPTsをリリースした。ニュース、トレンド、提案、要望、不満などの文章を元に、その意味に近い国会議事録の議論を出典元情報と共に検索できる。これにより、誰でも簡単に国会の議論を調査、取りまとめを実施することが可能となっている。
行政サービスにおいて、生成AIは政策の検討、法制化事務、情報提供、執行、事務などの様々な場面で活用が見込まれており、例えば自動処理による国会議事録検索サービスにより、国会の議論の調査や取りまとめが容易になっている。
経営、バックオフィスにおける活用(エクサウィザーズ)
バックオフィスにおいては、過去データを参照し経営や人事に活用、法務関連情報との連携を
引用元:第2 節 活用の現状・新たな潮流
行った契約書修正等において活用が見込まれている。
2023年5月、エクサウィザーズは、株主総会や決算説明会における想定問答の作成を支援する
「exaBase IRアシスタント powered by ChatGPT」を発表。2023年12月には生成AIを活用した採用業務効率化サービスに参入、最初の取組として、生成AI技術を応用したサービス開発力
と、HR Tech領域で蓄積した知見やデータを掛け合わせ、採用領域の業務効率化サービス「exaBase採用アシスタント」のβ版をリリースしている。

第1章 第9節:AIの動向
該当資料:第9 節 AIの動向
市場概況
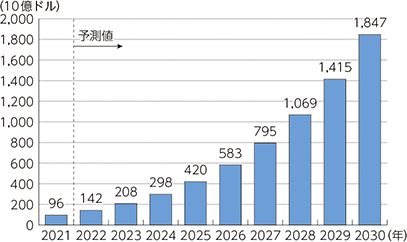
世界のAI市場規模(売上高)は、2022年には前年比78.4%増の18兆7,148億円まで成長する
と見込まれており、その後も2030年まで加速度的成長が予測されている。
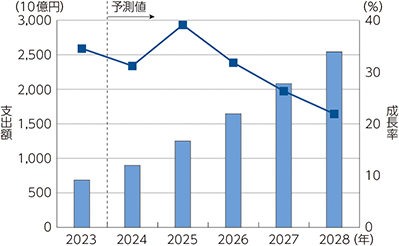
日本のAIシステム市場規模(支出額)は、2023年に6,858億7,300万円(前年比34.5%増)。
今後も成長を続け、2028年には2兆5,433億6,200万円まで拡大すると予測される。
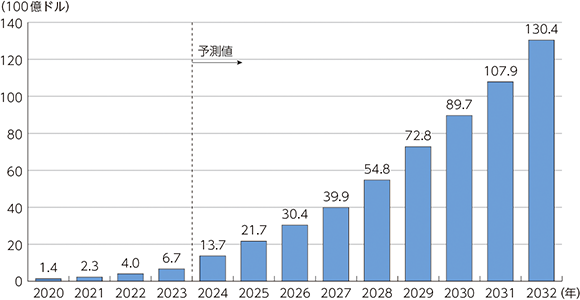
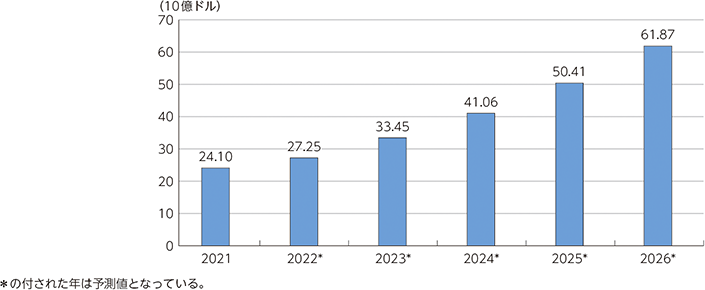
世界の生成AI市場は、2023年の670億ドルから2032年には1兆3,040億ドルと大幅な拡大が見込まれている。
背景には、GoogleのBard、OpenAIのChatGPT、Midjourney, Inc.のMidjourneyなど、近年の生成AIツールの爆発的な普及がある。
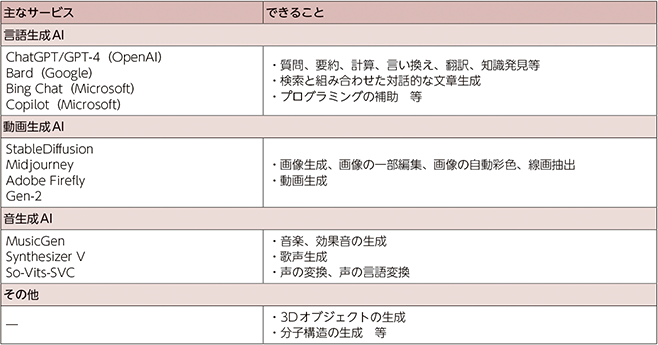
生成AIは文章だけではなく、画像、音声、動画など様々な種類のコンテンツ生成が可能で、その応用範囲は広い。
例えば、マーケティング、セールス、カスタマーサポート、データ分析、検索、教育、小説や法律等、多くの分野で活用されている。
さらに、コンピュータプログラムやデザインの生成も可能であり、人手不足対策や生産性向上の目的でも利用されている。
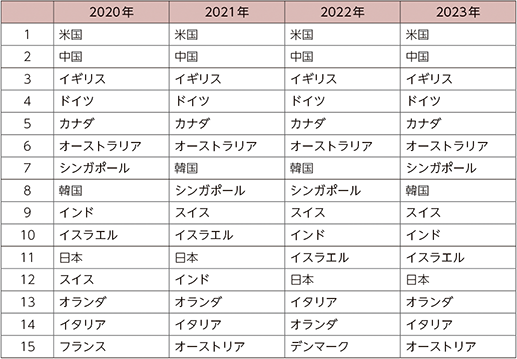
AIを巡る各国等の動向
AIはまだ技術的に発展途上であり、ビジネスの基礎となる研究が世界各地で行われている。
AIRankingsでは、論文数などを基に研究をリードする国や企業・大学等が公表されている。
国別では、米国、中国、イギリス、ドイツ、カナダの順となっており、日本は毎年11~12位となっている。
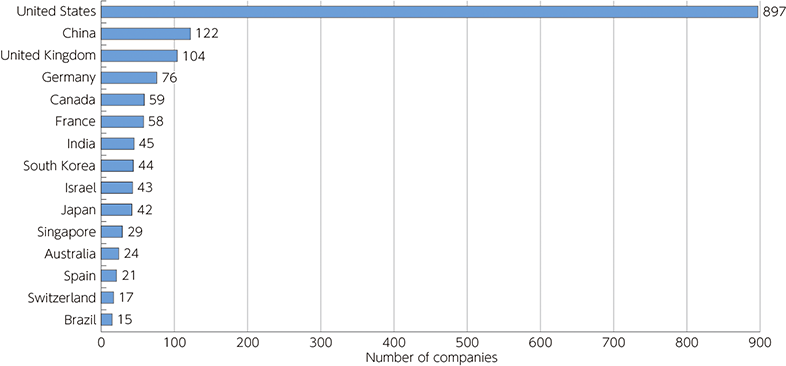
AI関連企業への投資も活発化しており、スタンフォード大学が公表した報告書「Artificial Intelligence Index Report 2024」によれば、2023年に新たに資金調達を受けたAI企業数は、米国が897社で1位、中国が122社で2位、日本が42社で10位となっている。
第3章 第1節:AI進展の経緯と生成AIのインパクト
AI進展の経緯
AI(人工知能)の歴史は1950年代から始まり、何度かブームと冬の時代を繰り返してきた。
探索・推論から始まった第1次AIブームは、音声認識等が組み込まれた第2次AIブームを経て、第
3次AIブームとしてディープラーニング(深層学習)をはじめとした革新的な技術が登場し、社
会で実用され得るAIが開発されて社会に浸透していった。
2022年頃からの生成AIの急速な普及により、現在は第4次AIブームに入ったとも言われている。
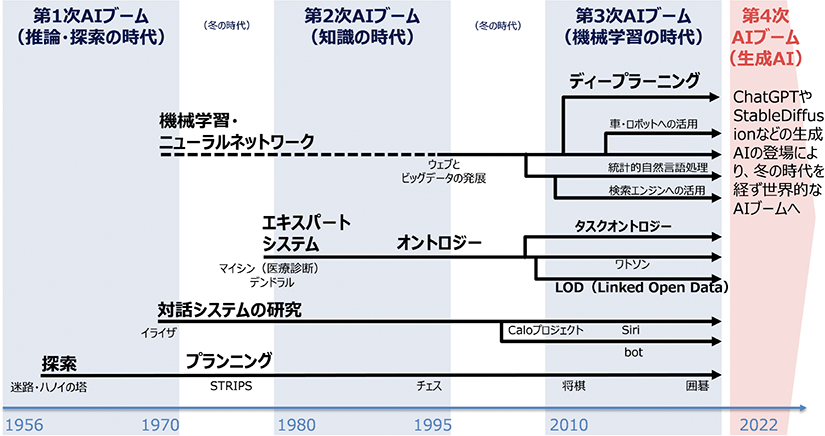
第1次AIブーム(1950年代後半~1960年代):推論・探索の時代
AIという言葉は、1956年に開催されたダートマス会議にて、アメリカの大学教授であったJ.
McCarthyにより提唱された。人工知能の概念が確立し、科学者たちにAIという言葉が認知され
るようになり、「推論」と「探索」の研究を中心に1960年代からAIの研究開発が活発化した。
「推論」は、人間の思考過程を記号で表現し実行するもの、「探索」は、目的達成のために手順や選択
肢を調べ、最適な解決策を見つけ出すもので、解くべき問題をコンピュータに適した形で記述し、
探索木などの手法によって解を提示するものである。
しかしながら、コンピュータの性能面で計算能力やデータ処理には限界があり、人間の知能のモデル化が困難であったため、当時のAIは「トイ・プロブレム」と呼ばれる簡単なパズルや迷路のような問題しか解くことができず、その実用化には課題があり、次第に冬の時代を迎えた。
第2次AIブーム(1980年代から1990年代):知識の時代
1980年代には、コンピュータの高性能化が進み、エキスパートシステム*1の登場により、各国
でAIの研究開発が再び活発化した。
ただし、コンピュータに学習させるデータ量が膨大であったため、当時のコンピュータの性能では処理ができず、専門家の知識の一部を模倣するに留まり、複雑な問題への対処ができないなどの課題があった。
さらに、学習データを人間の手でコンピュータが理解できるように記述する必要があり、大変な労力を必要とした。そのため、AIの研究は再び冬の時代を迎えた。
第3次AIブーム(2000年代~):機械学習の時代
1990年代にウェブサイトが公開され、2000年代に入ると家庭向けにもネットワークが普及しはじめ、データ流通量が飛躍的に増加し、研究に使用できるデータを大量に入手することができるようになった。
さらに、コンピュータの演算処理能力が向上したことにより、膨大な情報(ビッグデータ)の処理が可能となったことが大きな要因となり、機械学習が進化し、今日に至る第3次AIブームを迎えた。

機械学習の手法の1つであるディープラーニング(深層学習)は、AIのプログラムに人間の脳の仕組みをシミュレートさせるニューラルネットワークという考え方を発展させた技術である。
ディープラーニングにより、画像認識や自然言語処理、シミュレーションなどができるようになり、カメラの画像から人間の顔を識別することや、ロボットの自律運転の最適化などへの活用が広がった。

生成AIのインパクト
生成AIの急速な進化と普及
ディープラーニングの基盤技術により、AIの性能が飛躍的に向上したことで、様々なコンテン
ツを生成できるAIが誕生した。
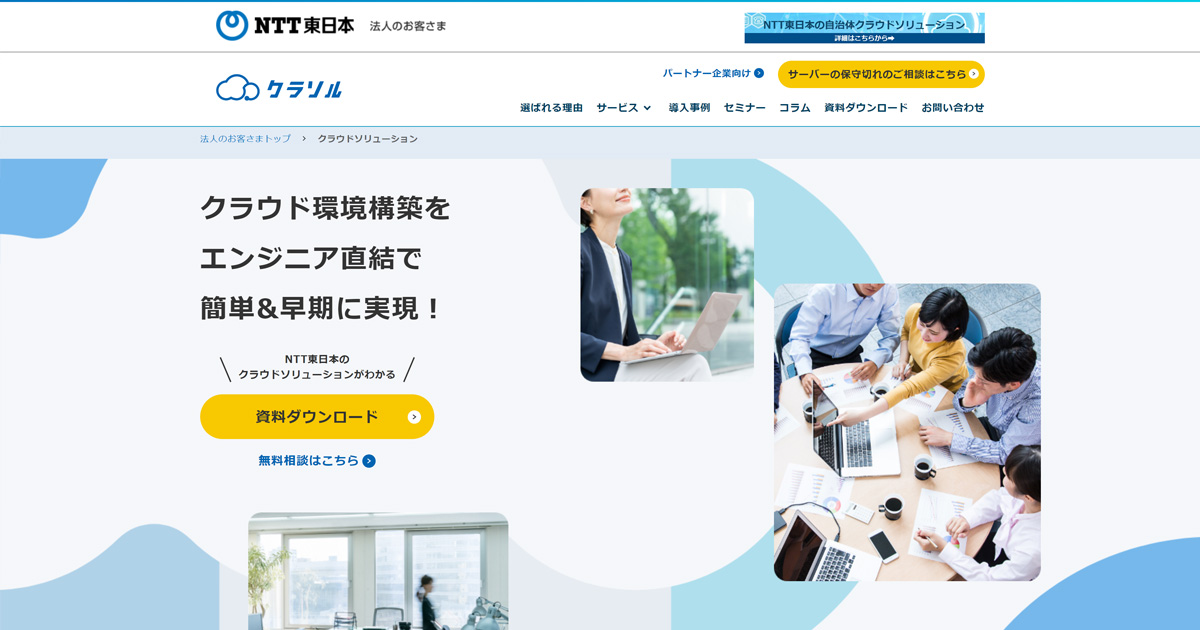
「生成AI」は、テキスト、画像、音声などを自律的に生成できるAI技術の総称であり、2022年のOpenAIによる対話型AI“ChatGPT”の発表を契機に、特に注目された分野である。
ChatGPTは、わずか5日で100万ユーザーを獲得し、さらに公開から2か月後にはユーザー数が1億人を突破するという、これまでのオンラインサービスなどと比較しても驚異的なスピードでユーザー数が拡大している。
OpenAI以外にも、大手企業からスタートアップ企業まで多くの企業が生成AIの開発を発表し、世界的な開発競争が起こっている。
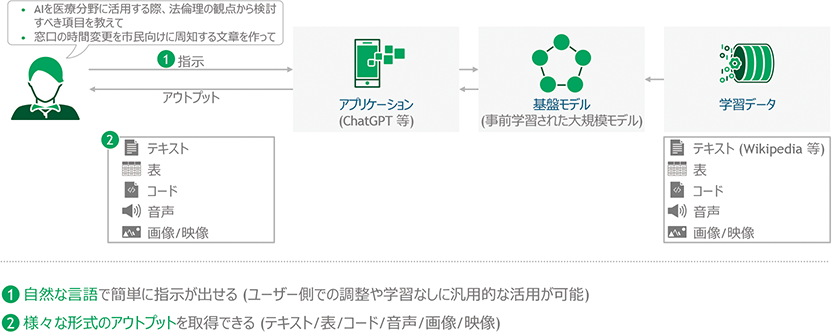
生成AIは、ユーザー側の調整やスキルなしに自然な言語で指示を出すだけで容易に活用できるものであり、テキスト、画像、映像等の多様な形式(マルチモーダル)のアウトプットが取得できるものである。
Center for Research on Foundation Models, 2021を基に分析
このブームの背景として、複数の要因が挙げられる。
まず、ディープラーニング(深層学習)やトランスフォーマーモデルの開発・大規模化により、自然言語処理や画像生成などのタスクにおけるモデルの精度が飛躍的に向上した。
そして、膨大な量のデータを用いてトレーニングされ、様々なタスクに適用可能な知識を獲得した基盤モデル(Foundation Model)や大規模言語モデル(LLM)の登場により、新たなタスクに対応するためにモデルを再トレーニングする必要がなくなり、開発や利用が大幅に容易化されるとともに、AIがより複雑なタスクをこなせるようになり、その有用性が広く認知された。
さらに、クラウドコンピューティングの発展やGPUの進化により計算資源が拡充されるとともにソースコードの公開(オープンソース化)によりAIの開発や利用が一般の開発者や企業にも開かれ、より広範な分野での活用が可能になったことも一因と言える。
また、使いやすいユーザーインターフェース(UI)、API(Application ProgrammingInterface)による提供が行われたことで、AIとの対話がより身近なものとなり、AIを利用して情報を取得したり、タスクを実行したりする際に、より直感的で使いやすい方法を享受できるようになった。
高い汎用性・マルチモーダル機能を通じてAIが単一のタスクに限定されず、様々なデータ形式や入力に対応し、多様なタスクを同時に処理できるようになったことで、その有用性が一層高まった。

また、人間の意図・価値観に合わせてAIを振る舞わせる仕組み(いわゆるAIアライメント)の取組が進んだことも挙げられる。
AIが人間と協調して働く環境が整い、多くの業界でAIの導入が促進された。
関連資料:国立研究開発法人科学振興機構 研究開発戦略センター,「人工知能研究の新潮流2」2023年7月
関連資料:生成AIで変わる未来の風景
生成AIによる経済効果
生成AIの登場により、我々の知的活動は大きく影響を受け、従来AIが適用しづらかった業務領域も含めて、コンテンツ制作、カスタマーサポート、建設分野等様々な業務領域での業務の変革が可能となる。
「生成AIの出現は、恐らく人類史上有数の革命といっても過言ではない。企業がセキュリティ上のリスクを恐れて活用しないことこそが最大のリスクであり、むしろ自社が次の時代の生成AIファースト企業になるつもりでAI活用を進めていくべき」とも言われている。
東京大学大学院工学系研究科技術経営戦略学専攻の今井翔太氏によると、「生成AIが役に立つかどうかといった議論をしている段階ではなく、使わなければ競合企業にあっという間に何倍の差がつけられるようなことが起こりうる転換点であり、既にソフトウェア産業においては、生成AIにより圧倒的な生産性の向上が実現されている」という。(2024年3月11日インタビュー実施)
引用元:第1 節 AI進展の経緯と生成AIのインパクト
2023年3月17日、OpenAIとペンシルバニア大学が発表した論文によれば、80%の労働者が、
彼らの持つタスクのうち少なくとも10%が大規模言語モデルの影響を受け、そのうち19%の労働
者は、50%のタスクで影響を受ける。
なかでも高賃金の職業、参入障壁の高い業界(データ処理系、保険、出版、ファンドなど)ではLLMの影響が大きいと予測されている。
一方で、生成AIによって大きなビジネス機会を引き出す可能性もある。
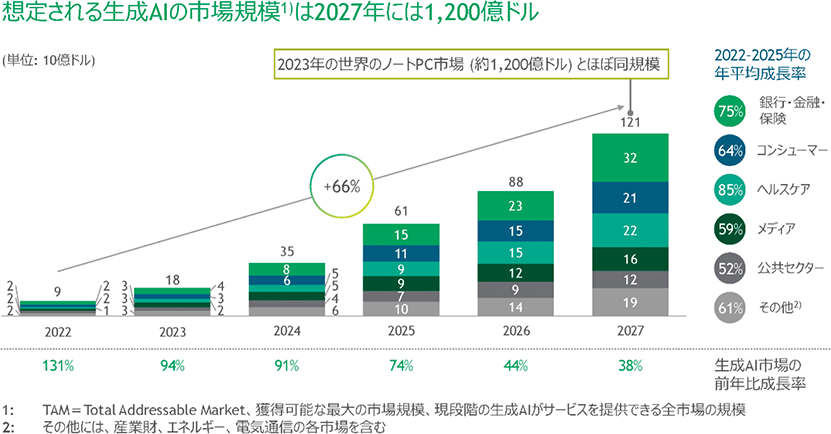
ボストンコンサルティンググループの分析によると、生成AIの市場規模について、2027年に1,200億ドル規模になると予想されている。最も大きな市場は「金融・銀行・保険」で、次に「ヘルスケア」、「コンシューマー」と続く。
第3章 第2節:AIの進化に伴い発展するテクノロジー
前節で振り返ったAIの進化は、他のテクノロジーにも影響を及ぼしている。
特に第3次AIブームにおけるディープラーニング(深層学習)の発展はXRを用いた仮想空間サービス、サービスロボット、自動運転等の開発に寄与し、また、生成AIの登場によってよりそれらの高度化を支えている。

AIが実際のサービスにおいて果たす機能には、「識別」「予測」「実行」という大きく3種類があるとされる。
それぞれの機能を利活用する場面は、製造や運送といったあらゆる産業分野に及びうる。
例えば、車両の自動運転であれば、これは画像認識・音声認識・状況判断・経路分析など様々な機能を、運輸分野に適した形で組み合わせて実用化したものである。
関連資料:総務省「ICTの進化が雇用と働き方に及ぼす影響に関する調査研究 報告書」2016年3月
ロボティクスにおいても、同様に複数の機能を組み合わせて実用化がなされている。

ここでは、生成AIを組み込むことでさらなる実用化が進んでいる仮想空間(メタバース・デジタルツイン)、ロボティクス、自動運転の動向について取り上げる。
仮想空間(メタバース・デジタルツイン)
メタバースとは、インターネット上に仮想的につくられた、いわばもう1つの世界であり、利用者は自分の代わりとなるアバターを操作し、他者と交流するものである。
仮想空間でありながら、メタバース上で購入した商品が後日自宅に届くなど、現実世界と連動したサービスも試験的に始まっているほか、仮想的なワークスペースとしてBtoBでの活用への広がりも期待されている。

また、現実空間を仮想空間に再現する概念として「デジタルツイン(Digital Twin)」がある。
デジタルツインとは、現実世界から集めたデータを基に仮想空間上に現実世界の要素を双子(ツイン)のように再現・構築し、様々なシミュレーションを行う技術である。
メタバースとデジタルツインは、それらが存在する空間が仮想空間である点は共通であるが、その空間に存在するものが実在しているものを再現しているかどうかを問わないメタバースに対して、デジタルツインは、シミュレーションを行うためのソリューションという位置づけであるため、現実世界を再現している点が異なる。
また、メタバースは、現実にはない空間でアバターを介して交流したり、ゲームをしたりというコミュニケーションが用途とされることが多いのに対して、デジタルツインは、現実世界では難しいようなシミュレーションを実施するために使われることが多い。

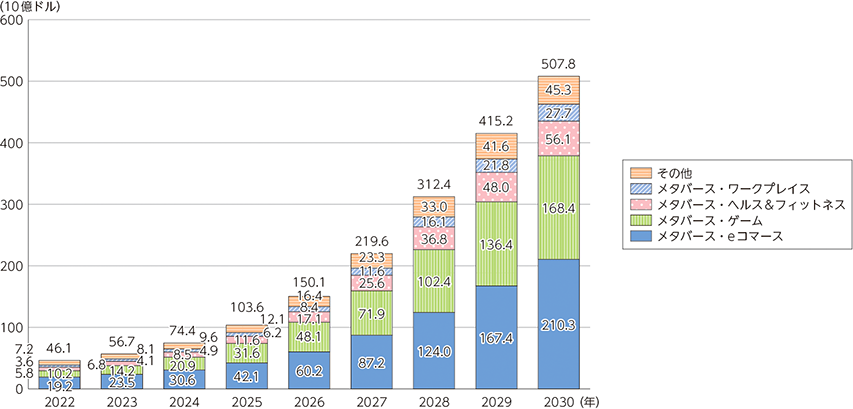
メタバースの市場規模は、2022年の461億ドルから2030年には5,078億ドルまで拡大すると
予測されている。
生成AIにより、2D画像・3Dモデルの自動生成やプログラム作成支援など、メタバース上の創作活動における一部の過程を簡略化することができる。
これにより、技術・知識的なハードルが下がり、利用者の拡大につながることが期待されている。
また、敵対的生成ネットワーク(GAN:Generative Adversarial Networks)などの機械学習を用いることで、デザイン経験のない人でも自分のアバター等を作ることができ、仮想空間の中に巨大な経済圏が誕生する可能性を秘めている。
ロボティクス
ロボットの開発は、1960年代に産業用として始まり、人間の手助けや危険な作業の代替として工業用途や軍事目的に利用された。
1990年代からは、工場等における産業用途だけでなく、介護や清掃、配達など一般社会におけるサービス用途での開発・活用や、家庭や個人の生活においても、掃除ロボットやコンパニオンロボットなど、さまざまな用途のロボット普及が進んできた。
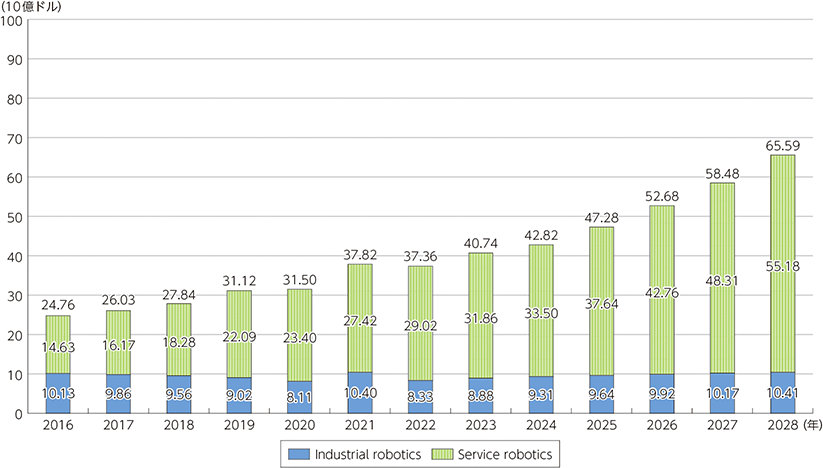
世界のロボットの市場は大幅な収益増が見込まれ、2024年には428億2,000万ドルに達すると予測されている。
市場内の様々なセグメントの中でも、サービス・ロボティクスは同年の市場規模が335億ドルと予測され、優位を占めると予想される。
この分野は、2024年から2028年までの年平均成長率(CAGR)が11.25%と、安定した成長が見込まれ、市場規模は2028年までに655.9億ドルに達すると推定される。
ロボットの開発・利用の拡大と人工知能(AI)の発展は相互に関わり合いながら進展してきた。
ロボットは、センサ(感知/識別)、知能・制御系(判断)、駆動系(行動)の3つの要素技術を有する知能化した機械システムと捉えられており、AIのディープラーニングをベースに強化学習を組み合わせることで、識別の能力が飛躍的に上がり、ロボットに備わっているカメラやセンサから大量のデータを収集し、分析することが可能になった。
生産工場などの現場では、品質検査や設備の予知保全などにすでにAIが活用されている。
また、介護ロボットや接客ロボットの実用化も進んできている。
音声認識技術と自然言語生成技術により、家庭用ロボットなどで人間がロボットと自然に対話を行えるようにもなってきた。
さらに、生成AIを行動生成AIとして、判断や駆動系にも使う試みがなされている。言語や画像
などマルチモーダルな情報を解釈できる生成AIが、ロボットのカメラ映像などから周囲の状況を
判断し、ユーザーからの指示を達成できるよう、ロボットの物理的な動作を繰り出すというもので
ある。
ただし、ロボットのフィジカルな動きにはまだ課題があり、触覚フィードバック、柔らかいハードウェアの開発や安全な力制御などの研究が重要になると考えられ、社会での実用化にはまだ時間がかかる*6*7。


通常、ロボットを動かすにはプログラミングが必要であるが、今後、生成AIが人との対話を通じて自らプログラミングができるようになれば、人の言葉を理解して即座にプログラミングし、ロボットを制御する未来も期待される。
自動運転技術
自律的な自動運転技術においては、システムが行う認知、判断、操作の3つのプロセスにおいてAIの技術が活用されている。
AIは、車両に搭載されたカメラやセンサから得られた周辺の情報を認識処理し、通行人や障害物を避けて車両を安全に走行させる。
カメラやセンサからとらえた情報をもとに、前方を走行する車両や歩行者などがどのような挙動を見せるかなどの予測や、それらを踏まえて車両をどのように制御するべきかの判断や意思決定においても生成AIが活用されている。
自動車の安全運転をサポートするのも、AIの活躍が期待されている重要な役割である。
さらに、生成AIによる学習機能により、高度なルート最適化が行えるようになったほか、生成AIの音声認識技術も活用されており、運転者の声で自動車に指示を出すことができる。


今後の完全自動運転の実現には、画像認識だけでなく、音声などを認識し搭乗者とのコミュニケーションを行うなど、様々な部分でマルチモーダルな生成AIが必要となっており、実際、自動車に生成AIを導入する動きが増えている。
世界の自動運転車の市場規模は、2021年に240億ドルを超えた。
市場は今後も成長し、2026年には約620億ドルの規模に達すると予想されている。
第4章 第1節:AIの進化に伴う課題と現状の取組
進化してきたAIは我々の生活に便利さをもたらす一方で、活用に当たっては留意すべきリスクや課題も存在している。
これまで、AI全般についても、不適切なデータや偏ったデータを学習に使用することでモデルのバイアスや誤差が増加し、予測の信頼性が低下する点や、多くの従来の機械学習モデルについてブラックボックス(透明性の欠如)となっていてその内部動作が理解しにくく、重要な意思決定の場面で問題を引き起こす可能性が指摘されていた。
これに加え、生成AIが爆発的に発展・普及する中で、特有の課題・リスクも明らかになってきた。
以下に生成AIが抱えるリスク・課題を技術的/社会・経済的な観点から概観する。
生成AIが抱える課題
2024年4月に総務省・経済産業省が策定した「AI事業者ガイドライン(第1.0版)」では、(従来から存在する)AIによるリスクに加えて、生成AIによって顕在化したリスクについて例示している。

例えば、従来から存在するAIによるリスクとして、バイアスのある結果及び差別的な結果が出力されてしまう、フィルターバブル及びエコーチェンバー現象が生じてしまう、データ汚染攻撃のリスク(AIの学習実施時の性能劣化及び誤分類につながるような学習データの混入等)、AIの利用拡大に伴う計算リソースの拡大によるエネルギー使用量及び環境負荷等が挙げられている。
「フィルターバブル」とは、アルゴリズムがネット利用者個人の検索履歴やクリック履歴を分析し学習することで、個々のユーザーにとっては望むと望まざるとにかかわらず見たい情報が優先的に表示され、利用者の観点に合わない情報からは隔離され、自身の考え方や価値観の「バブル(泡)」
の中に孤立するという情報環境を指す。
「エコーチェンバー」とは、同じ意見を持つ人々が集まり、自分たちの意見を強化し合うことで、自分の意見を間違いないものと信じ込み、多様な視点に触れることができなくなってしまう現象を指す。
また、生成AIによって顕在化したリスクとしては、ハルシネーション等が挙げられる。
生成AIは事実に基づかない誤った情報をもっともらしく生成することがあり、これをハルシネーション(幻覚)と呼ぶ。
技術的な対策が検討されているものの完全に抑制できるものではないため、生成AIを活用する際には、ハルシネーションが起こる可能性を念頭に置き、検索を併用するなど、ユーザーは生成AIの出力した答えが正しいかどうかを確認することが望ましい。
また、生成AIの利用において、個人情報や機密情報がプロンプトとして入力され、そのAIからの出力等を通じて流出してしまうリスクや、ディープフェイクによる偽画像及び偽動画といった偽・誤情報を鵜呑みにしてしまい、情報操作や世論工作に使われるといったリスク、既存の情報に基づいてAIにより生成された回答を鵜呑みにする状況が続くと、既存の情報に含まれる偏見を増幅し、不公平あるいは差別的な出力が継続/拡大する(バイアスを再生成する)リスクがあること等も指摘されている。
同ガイドラインでは、このような「リスクの存在を理由として直ちにAIの開発・提供・利用を妨げるものではない」としたうえで、「リスクを認識し、リスクの許容性及び便益とのバランスを検討したうえで、積極的にAIの開発・提供・利用を行うことを通じて、競争力の強化、価値の創出、ひいてはイノベーションに繋げることが期待される」としている。
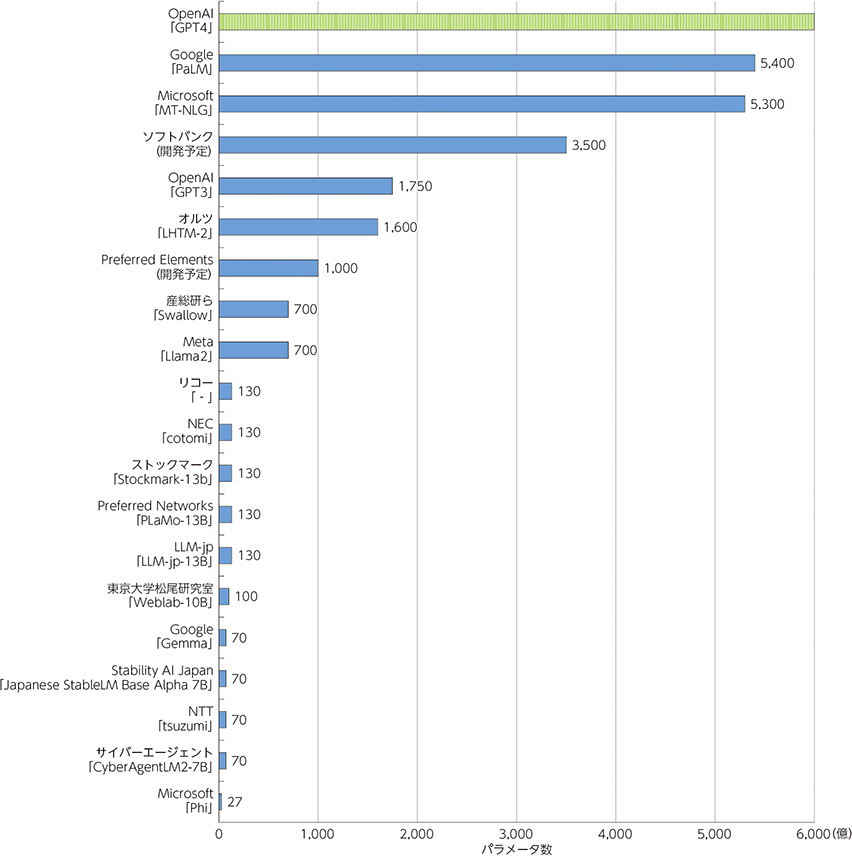
主要なLLMの概要
生成AIの基盤となる大規模言語モデル(LLM)の開発では、マイクロソフトやグーグルなど米国ビックテック企業などが先行している状況にある。
しかし、日本以外の企業・研究機関がクローズに研究開発を進めたLLMを活用するだけでは、LLM構築の過程がブラックボックス化してしまい、LLMを活用する際の権利侵害や情報漏えいなどの懸念を払拭できない。
日本語に強いLLMの利活用のためには、構築の過程や用いるデータが明らかな、透明性の高い安心して利活用できる国産のLLM構築が必要となる。

すでに日本の企業においても、独自にLLM開発に取り組んでおり、ここではその動向を紹介する。
ビッグテック企業が開発したLLMと比べると、日本では、中規模モデルのLLMが開発されている傾向が見られる。
国産LLMの開発
NICTによる国産LLMの開発
2023年7月に、国立研究開発法人情報通信研究機構(NICT)は、ノイズに相当するテキストが少ない350GBの高品質な独自の日本語Webテキストを用いて、400億パラメータの生成系の大規模言語モデルを開発した旨を発表した。
発表によれば、NICTの開発したLLMについてはファインチューニングや強化学習は未実施であり、性能面ではChatGPT等と比較できるレベルではないものの、日本語でのやり取りが可能な水準に到達しているとしており、今後は、学習テキストについて、日本語を中心として更に大規模化していくこととしている。
また、GPT-3と同規模の1,790億パラメータのモデルの事前学習に取り組み、適切な学習の設定等を探索していく予定である。
さらに、より大規模な事前学習用データ、大規模な言語モデルの構築に際し、ポジティブ・ネ
ガティブ両方の要素に関して改善を図るとともに、WISDOM X、MICSUS等既存のアプリケー
ションやシステムの高度化等にも取り組む予定としている(2024年5月現在、NICTではさらに
開発を進め、最大3,110億パラメータのLLMを開発するなど、複数種類のLLMを開発しパラメー
タや学習データの違いによる性能への影響等を研究している)。

サイバーエージェントが開発した日本語LLM「CyberAgentLM」
2023年5月、サイバーエージェントが最大68億パラメータの日本語LLMを開発したことを発表した。
2023年11月には、より高性能な70億パラメータ、32,000トークン対応の日本語LLM「CyberAgentLM2-7B」と、チャット形式でチューニングを行った「CyberAgentLM2-7B-Chat」
の種類を公開した。
日本語の文章として約50,000文字相当の大容量テキストを処理可能である。
商用利用が可能なApacheLicense2.0で提供されている。


日本電信電話(NTT)が開発した日本語LLM「tsuzumi」
2023年11月にNTTが開発した、軽量かつ世界トップレベルの日本語処理能力を持つLLMモデル「tsuzumi」が発表された。
「tsuzumi」のパラメータサイズは6~70億と軽量であり、クラウド提供型LLMの課題である学習やチューニングに必要なコストを低減できる。
「tsuzumi」は英語と日本語に対応しているほか、視覚や聴覚などのモーダルに対応し、特定の業界や企業組織に特化したチューニングが可能である。
2024年3月から商用サービスが開始されており、今後はチューニング機能の充実やマルチモーダルの実装も順次展開される見込みである。

生成AIが及ぼす課題
前述のような生成AI自身が抱える制約事項のほか、生成AIの進展・普及には、それに伴う社会
的・経済的な課題も多く、国内外のテック事業者、プラットフォーム事業者、業界団体や政府等に
よる対策検討が進められている。
偽・誤情報の流通・拡散等の課題及び対策
「ディープフェイク」とは、「ディープラーニング(深層学習)」と「フェイク(偽物)」を組み合わせた造語で、本物又は真実であるかのように誤って表示し、人々が発言又は行動していない言動を行っているかのような描写をすることを特徴とする、AI技術を用いて合成された音声、画像あるいは動画コンテンツのことをいう。
近年、世界各国でこれらディープフェイクによる情報操作や犯罪利用が増加しており、その対策には各方面からの取組が行われているものの、いたちごっこの様相を呈している。
ディープフェイクによる課題
AIにより生成された偽・誤情報の流通・拡散
生成AIの進歩により、非常に高品質なテキスト、画像、音声、動画を生成することが可能になり、リアルで信憑性の高い偽・誤情報を作成することが可能になった。
ディープフェイク技術を用いれば、実在する人物が実際には言っていないことを本当に話しているかのような動画を簡単に作成することができる。
我が国でも、生成AIを利用して作られた岸田総理大臣の偽動画がSNS上で拡散した事例が発生した*9。

2024年1月1日に発生した能登半島地震の際にも、東日本大震災の時の津波映像や静岡県熱海市で2021年に起きた大規模土石流の映像などをあたかも能登半島地震と結びつけた投稿がSNS上で多数投稿され、大量に閲覧・拡散された。

2020年には、新型コロナウイルス感染症と5G電波との関係を謳う偽情報が携帯電話基地局の破壊活動を招くなど社会的影響も生じさせている。

SNSなど様々なデジタルサービスが普及し、あらゆる主体が情報の発信者となり、インターネッ
ト上では膨大な情報やデータが流通するようになったが、このような情報過多の社会においては、
供給される情報量に比して、我々が支払えるアテンションないし消費時間が希少となるため、それ
らが経済的価値を持って市場で流通するようになる。
このことはアテンション・エコノミーと呼ばれ、プラットフォーム事業者が、受信者のアテンションを得やすい刺激的な情報を優先表示するようになるなど、経済的インセンティブ(広告収入)により偽・誤情報が発信・拡散されたり、インターネット上での炎上を助長させたりする構造となっている。
偽・誤情報の拡散は世界的に問題となっており、2024年1月、世界経済フォーラムは、社会や政治の分断を拡大させるおそれがあるとして、今後2年間で予想される最も深刻なリスクとして「偽情報」を挙げた。

特に2024年は、米国をはじめ、バングラデシュ、インドネシア、パキスタン、インド等、50か国余りで国政選挙が予定されている。
既にインドネシア大統領選の際のディープフェイク動画の流布や、米大統領選の予備選の前に偽の音声でバイデン米大統領になりすます悪質な電話等、生成AIを利用したディープフェイクによる情報操作の事例が確認されている。


その他犯罪利用
生成AIが、情報操作のみならず、犯罪に利用されるケースも増えている。
米国OpenAIのチャットボット(自動会話プログラム)であるChatGPTに用いられているものと同じAIが悪用され、「悪いGPT(BadGPT)」や「詐欺GPT(FraudGPT)」と呼ばれる不正チャットボットによってフィッシング詐欺メールが量産されている。
このようなハッキングツールは、OpenAIがChatGPTを公開した2022年11月の数か月後には闇サイト上で確認されるようになり、ChatGPT公開後の12か月間で、フィッシング詐欺メールは1,265%増加し、一日平均約3万1,000件のフィッシング攻撃が発生しているという試算もある。

ディープフェイクを利用した犯罪には、AIの画像生成能力を悪用した恐喝行為もある。
SNS等で共有された一般的な写真画像をAIで不適切な内容に変換し、被害者を脅迫するというもので、米国連邦捜査局(FBI)は、被害者には未成年の子供も含まれると警告している。

ディープフェイクによる情報操作や犯罪利用への対策
欧州連合(EU)
偽・誤情報に関する法規制で先行するのは欧州連合(以下「EU」という。)である。
2022年11月に発効した「デジタルサービス法(The Digital Services Act)」(以下「DSA」という。)は、超大規模オンラインプラットフォーム(VLOP)などに対して、自身の提供するサービスのリスク評価(偽情報に関するものを含む)やリスク軽減措置の実施を義務付けており、違反企業には最大で世界年間売上高の6%の制裁金が科されることとなっている。
実際に、EUの執行機関である欧州委員会(以下「EC」という。)は、イスラエルに対するハマス等によるテロ攻撃に関わる違法コンテンツの拡散等を踏まえ、X(旧Twitter)がDSAを遵守していない可能性があるとして、違法コンテンツの拡散への対応のほか、プラットフォーム上の情報操作への対抗措置の有効性等の領域について、2023年12月に正式な調査を開始した。
プラットフォーム上の情報操作への対抗措置に関し、ECは、特に、投稿に第三者が匿名で注釈を加える「コミュニティ・ノート」という機能等の有効性に焦点を当てる方針であるとしている。
2024年3月、欧州議会は、AIに関する世界初の包括的な法的枠組みと位置づける「AI法(AI Act)」の最終案を可決し、同年5月にEU理事会にて正式承認され、同法が成立した。
同法は一部ディープフェイクに関する規制も含み、2026年頃には本格的に適用される見込みである。
英国
英国では、2023年10月に発効された「オンライン安全法(Online Safety Act 2023)」に、虚偽であると知っている情報を受信者に心理的または身体的危害を与えることを意図してインターネット上で送信した者に、6か月の禁錮刑を科す内容が含まれている。
特に、相手に苦痛、不安や屈辱等を与える加害意図や、自分が性的満足を得ようとする意図があったと立証されれば、最高刑が懲役2年となる。
米国
米国においては、2023年7月、バイデン政権が、AI開発を主導するGoogle、Meta PlatformsやOpenAI等の7社*22から、AIの安全性や透明性向上に取り組む自主的なコミットメントを得たと発表した。

同年9月には、新たにIBM、Adobe、NVIDIA等8社が合意し*25、同15社はディープフェイク対策として、真贋を示す目印をデータに忍ばせて識別を可能にする「電子透かし」等、AIによる生成を識別するための技術開発を推進している。

また、米国の一部の州において、ポルノや選挙活動等の特定の目的下でのディープフェイクに関する規制が見られる。
例えば、カリフォルニア、テキサス、イリノイ、ニューヨーク等9州では、相手の同意の無いディープ
フェイクを用いたポルノ画像や動画の配布を刑事犯罪として規定しているほか、テキサス州やカリフォルニア州では、公職の候補者に対するディープフェイク等の発信に係る規制法を設けている。
なお、米国連邦法においては、国防総省や全米科学財団等の連邦機関に対し、ディープフェイクを含む偽情報に関する調査研究の強化等を求める法律が制定されている*27。
関連資料:IDENTIFYING OUTPUTS OF GENERATIVE ADVERSARIAL NETWORKS ACT
他方、民間事業者に対しては、1996年成立の「通信品位法(Communications Decency Act)」第230条(通称Section230)において、プロバイダは第三者が発信する情報に原則として責任を負わず、有害な内容の削除に責任を問われないと規定されているが、バイデン政権では、偽・誤情報に関してプラットフォーム事業者に一定の責任を求めるよう、法改正しようとする方向で議論が行われている。
日本
我が国におけるデジタル空間の情報流通の健全性確保に向けては、総務省が2023年11月から「デジタル空間における情報流通の健全性確保の在り方に関する検討会」を開催しており、2024年(令和6年)夏頃までに一定のとりまとめを公表予定である。
技術的な対策としては、インターネット上のニュース記事や広告などの情報コンテンツに、発信
者情報を紐付けるオリジネータープロファイル(OP、Originator Profile)技術の研究開発が進
んでいる。

この技術により、なりすましや改変が見える化されることで、Web利用者が透明性の高いコンテンツを閲覧できるようになる、フェイクニュースや安易な関心獲得による広告収益が得られにくくなり、適正なWebメディアやコンテンツの配信者の権利利益侵害を低減できるようになる、広告枠が設置されるWebコンテンツの発信者が明確になることで、広告主が安心して広告出稿ができるようになるといった効果が期待される。
また、国立情報学研究所(以下「NII」という。)がフェイク技術対策に関する研究に早期から取り組んでおり、2021年9月には、AIにより生成されたフェイク顔画像を自動判定するツール「SYNTHETIQ VISION:Synthetic video detector」を開発した。

これは真贋判定をしたい画像をサーバーにアップロードすると、同ツールがフェイクかどうかを判定するものである。
現在NIIでは、更に進んだディープフェイク対策技術「Cyber Vaccine(サイバーワクチン)」を開発中であり、これが実現すると、真贋判定だけでなく、どこが改竄されたのか等の情報も得ることができるようになると期待されている*30*31。

ただし、これらの対策には、真贋判定ツールの精度という課題もある。OpenAIによると、同社が自主開発した判定ツールが生成AI(主にChatGPT)製の文書を正しくAIによるものと判定する確率は26%で、逆に人間が書いた文書を誤って生成AIによると判定してしまう「偽陽性」の確率も9%あったという。そのため、この程度の精度では実際には有効な判定ツールとはならず、同社は当該ツールの提供を中止している。今後テキストや画像、音声等の生成AIと、それらの判定ツールが互いに競い合う形で双方の技術改良が進んでいく可能性が高いため、そのような技術を使っても、フェイク情報を正確に判別するのは難しいと見られている。
著作権を含む知的財産権等に関する議論
生成AIの生成物は、主に、文章、画像、音楽・音声の3種類である。
これらは、大量のデータからその特徴を学習し、プロンプト(入力)に応じて適切な結果を出力する「機械学習」の手法を用いて開発されている。
この際、データを収集・複製し、学習用データセットを作成したり、データセットを学習に利用して、AI(学習済みモデル)を開発することがオリジナルデータの制作者等の権利を侵害しないかという開発・学習段階の論点がある。
また、生成AIを利用して画像等を生成したり、生成した画像等をアップロードして公表、生成した画像等の複製物(イラスト集など)を販売する際に、既存の画像等の作品と類似したものを使ってしまう等の場合に、既存作品の制作者の権利の侵害等になることがある(生成・利用段階の論点)。
生成AIの進展・普及に伴う著作権を含む知的財産権等に関わる問題提起
生成AIに関連する著作権や肖像権の侵害問題は国際的に注目されており、多くの訴訟が発生している。
米国では、2022年11月、GitHub Copilotの開発に関連して、学習に使用しているオープンソースコードがプログラマーの著作権を侵害している可能性があるとして、Microsoft、GitHub、OpenAIに対する集団訴訟が提訴されたほか、2023年7月には、米国の作家3名がOpenAIとMeta Platformsの2社を提訴した訴訟も発生した。

同集団訴訟は、ChatGPTの機械学習に作家の著作物が無断で使用されたことによる損害賠償を請求するもので、同訴訟の結果、OpenAIは学習データから著作物を削除するのではなく、著作権侵害で訴えられた場合の訴訟費用を負担することを表明することとなった。

新聞社、通信社等のメディアでのAIの活用は慎重なものとなっている。
米国のAssociated Press(AP通信)は2023年7月にOpenAIとの提携を発表し、生成AIをニュース報道に生かす方法等について共同で研究する契約を結んだが、8月にはAIを配信可能なコンテンツ作成のために使用しないとした。
一方、New York TimesはAIによる記事の無断使用でOpenAIとMicrosoftを訴え、これが報道機関による初の訴訟提起となった。
日本国内においても、新聞・通信各社は、生成AIによる報道記事の無断使用について、生成AIによる記事の無断使用は許容できず、根本的な法改正に向けた検討を求める意見を表明している。
日本では、生成AI技術の発展と急速な普及に伴って権利者やAI開発者から著作権などの知的財産権の侵害に関する懸念の声が上がったことを踏まえ、2024年3月、文化審議会著作権分科会法制度小委員会において、「AIと著作権に関する考え方について」がとりまとめられるとともに、(著作権を含む)知的財産権との関係について、2024年5月、AI時代の知的財産権検討会より、「AI時代の知的財産権検討会 中間とりまとめ」が公表された。
著作権を含む知的財産権等の侵害リスクに対する取組
生成AIの利用に際しての著作権等の権利侵害対策に向けては、データ・コンテンツの権利保持者とAI事業者双方が、互いの契約の中で対応を行うこと等が考えられる。
技術的には、生成AI生成物であることの表示を可能とする電子透かしの実用化や、OpenAIによる知的財産権を侵害する恐れのあるデータ・コンテンツのAI入出力を抑制する仕様の提供等がある一方で、New York Times、CNN、Bloomberg、Reuters、日本経済新聞等の国内外のメディア側も、OpenAI等AI
事業者のGPTボットのブロックを行う等の対策で自衛している。
技術を活用しながら著作権侵害の法的リスクに対してコミットする取組もある。
Microsoftは、大規模言語モデル(Large Language Model:LLM)を組み込んだ自社の生産性向上ツール「Microsoft Copilot」に対する法的リスクに対して責任を負う、「Copilot Copyright Commitment」を2023年9月に発表している。
Microsoft Copilotで生成した出力結果を使用して、著作権上の異議を申し立てられた場合、Microsoftが責任をとる仕組みとなっている。

著作物を使用しない、あるいは許諾済みの著作物を活用する方法で著作権等侵害のリスクを回避する方法もある。
例えば、Adobeが提供する「Adobe Firefly」は、オープンライセンス等、著作権の問題の無い画像を学習段階で利用しており、著作権侵害の心配なく生成した画像の商用利用が可能としている。
第4章 第2節:AIに関する各国の対応
該当資料:第2 節 AIに関する各国の対応
こうした生成AIをはじめとするAIの急速な普及のなかで生じた倫理的・社会的な課題に対処す
るためには、国内のみならず、諸外国と協調した取組が必要である。
国際的な議論の動向
広島AIプロセス
AIについての倫理的・社会的課題に対する議論は2015年頃から活発化しており、我が国は、早期からG7/G20や経済協力開発機構(以下「OECD」という。)等における議論を先導し、AI原則の策定に重要な役割を果たしてきた。
2016年4月に高松で開催されたG7情報通信大臣会合において、日本からAIの開発原則に関する議論が提案され、その後OECDで合意されたAI原則が2019年5月に公開されたことを受けて、同年6月のG20首脳会合にて、「G20 AI原則」が合意された。

2019~2020年には、AI原則については国際的なコンセンサスが形成されつつあり、同原則を社会に実装するための具体的な制度や規律の策定に関する議論に移行している。
更には、2022年の生成AIの急速な普及により、G7等の国際協調の場においても、また各国においても、AIガバナンスの議論が活発化している。
2023年4月、群馬県高崎市でG7群馬高崎デジタル・技術大臣会合が開催され、生成AIの急速な普及と進展を背景に、「責任あるAIとAIガバナンスの推進」などについて議論が交わされた。
同会合では、G7のメンバー間で異なる、AIガバナンスの枠組み間の相互運用性の重要性が確認され「責任あるAIとAIガバナンスの推進」、「安全で強靱性のあるデジタルインフラ」、「自由でオープンなインターネットの維持・推進」等の6つのテーマからなる閣僚宣言が取りまとめられた。
同宣言はその後、5月に広島で開催された主要7か国首脳会議(G7広島サミット)における議論に反映され、当該サミットの首脳コミュニケ(宣言)において、生成AIに関する議論のための広島AIプロセスの創設が指示された。具体的には、OECDやGPAI(後述)等の関係機関と協力し、G7の作業部会にて調査・検討を進めることとなった。
2023年9月には、7月~8月にOECDが起草したレポートや、生成AI等を含む高度なAIシステムの開発に関して議論すべく閣僚級会合が開催され、透明性、偽情報、知的財産権、プライバシーと個人情報保護等が優先課題であることが確認された。
その後10月30日に「広島AIプロセスに関するG7首脳声明」が発出され、まずは高度なAIシステムの開発者を対象とした国際指針と行動規範が公表された。
更に同年12月には、AIに関するプロジェクトベースの協力を含む広島AIプロセス包括的政策枠組みや、広島AIプロセスを前進させるための作業計画が発表されている。
OECD/GPAI/UNESCOの動き
OECD
OECD、GPAI、UNESCO等、多くの国際機関もグローバルな観点からAIガバナンス制度の検討を進めている。
2019年5月にOECDのAI原則が公開されて以降、各種OECDレポートの発表やプロジェクトの推進等、G7との連携の下、積極的な活動が行われている。
また、OECD、GPAI、UNESCOの3機関は、2023年9月に「生成AI時代の信頼に関するグローバルチャレンジ(Global Challenge to Build Trust in the Age of Generative AI)」を発表し、G7の包括
枠組みを踏まえ、偽情報やディープフェイク等による社会的リスクに対し、イノベーティブな解決
策を進めるグローバルな連携プロジェクトを推進している。
2024年5月に開催されたOECD閣僚理事会では、生成AIに関するサイドイベント「安全、安
心で信頼できるAIに向けて:包摂的なグローバルAIガバナンスの促進」において、岸田総理大臣
から49か国・地域の参加を得て広島AIプロセスの精神に賛同する国々の自発的な枠組みである
「広島AIプロセス フレンズグループ」を立ち上げることを発表した。

GPAI
「AIに関するグローバルパートナーシップ(Global Partnership on AI)」(以下「GPAI」という。)は、2020年、人間中心の考え方に立ち、「責任あるAI」の開発・利用を実現するために、OECDとG7の共同声明により創設された。
同組織は、OECDが事務局を務め、価値観を共有する政府、国際機関、産業界、有識者等からなる官民国際連携組織で、現在29か国が参加している。
GPAIには、「責任あるAI」、「データ・ガバナンス」、「仕事の未来」、「イノベーションと商業化」という4つの研究部会が設置されており、専門家による議論と実践的な調査が実施されている。
GPAIの年次サミットである「GPAIサミット2023」においては、新たなGPAI専門家支援センターである、GPAI東京専門家支援センターの立ち上げが承認された。
同センターでは、生成AIに関する調査・分析等のプロジェクトを先行的に実施する予定となっている。
UNESCO
国連教育科学文化機関(UNESCO)も、2021年にAIの倫理に関する勧告「UNESCO Recommendation on the Ethics of Artificial Intelligence」を採択し、各国における取組を支
援している。
2023年9月には、教育・研究に関する初の生成AIのグローバルガイダンスである「教育・研究分野における生成AIのガイダンス(Guidance for generative AI in education and research)」を公表し、生成AIの定義や説明、倫理的及び政策的な論点と教育分野への示唆、規制の検討に必要なステップ、カリキュラムデザインや学習等について紹介している。
ほとんどの生成AIが主として大人向けに設計されていることから、教育現場での使用は13歳以上に制限すべきと提案し、各国政府には、データのプライバシー保護を含む適切な規制や教員研修等を求めてい
る。
AI安全性サミット
2023年5月、OpenAIは、今後10年以内に人間の専門家のスキルレベルを超えるAIシステムが実現する可能性があると発表した。
同社はこれを「フロンティアAI(Frontier AI)」と命名し、核エネルギーや合成生物学等の人類の存在上のリスクに鑑みて、事後的対応ではなく国際的な規制を検討すべきとした。
これを受けてスナク英国首相は、2023年11月1日~2日に英国ブレッチリーにて、「AI安全性サミット」を開催した。
従来の人権や公平性といった「AI倫理」を超えて、AIによる「深刻且つ破滅的な危害」の防止を視野に入れた「AIの安全性」について議論されたことが特徴的である。
本サミットの成果文書として「ブレッチリー宣言」が採択された。
また、英国はAIセーフティ・インスティテュートを設置することについても決定した。
2024年5月21日~22日には、韓国・英国共催により「AIソウル・サミット」が開催された(21日の首脳セッションはオンライン開催、22日の閣僚セッションはソウルで対面開催)。
AI安全性の議論を深めるとともに、AI開発におけるイノベーション促進及びAIの恩恵の公平な享受につ
いて議論が行われ、首脳級の成果文書として「安全、革新的で包摂的なAIのためのソウル宣言」及び付録「AI安全性の科学に関する国際協力に向けたソウル意図表明」、閣僚級の成果文書として「安全、革新的で包摂的なAIの発展のためのソウル閣僚声明」が採択された。
今後、2025年2月にフランスにて次回会合が開催される予定となっている。
国際連合の動向
前項のとおり、フロンティアAIに対する国際的なガバナンス体制への関心の高まりを受けて、2023年7月の国連安全保障理事会においては、英国主導でAIに関する議論が行われた。
グテーレス国連事務総長は同年10月に、事務総長の諮問機関として、AIハイレベル諮問機関を立ち上げ、日本人の構成員も参加している。
また、2024年3月21日、国連総会において、日本も共同提案国である、「持続可能な開発のための安全、安心で信頼できるAIシステムに係る機会確保に関する決議」をコンセンサスで採択し、同決議案は、安全、安心で信頼できるAIに関する初めての国連総会決議となった。
同決議案は「持続可能な開発のための2030アジェンダ」の達成に向けた進捗を加速し、デジタルディバイドを解消するため、安全、安心で信頼できるAIを促進しており、加盟国に対し、安全、安心で信頼できるAIに関連する規制・ガバナンスアプローチの策定・支持を推奨している。
さらに、加盟国及びステークホルダーに対し、AI設計・開発中のリスク特定・評価・軽減のためのイノベーション促進や、データ保全のためのリスク管理メカニズムの策定・実施・公表等の手段を通じて、AIシステムが世界の課題に対応できるための環境を整備するよう推奨している。
また、AIシステムのライフサイクルを通じて、人権及び基本的自由が尊重され、保護され、促進されるべきことを強調している。
同決議案は、AIの国際ルールづくりに向け、広島AIプロセスをはじめ、G7やG20、OECD等で進めてきた議論を反映したものであり、国連総会決議には国際法上の拘束力はないものの、コンセンサスで加盟国が採択したということから、国際社会の総意としての政治的な重みを持つものである。
各国における法規制・ガイドライン等の整備動向
現在、AIに関する法制度や国際標準に関する議論が世界各国で活発に行われており、2023年はEUのAI法の欧州議会での採択、米国のAIの安全性に係る大統領令、日本のAI関連事業者向けのガイドライン案の公表など、AI政策にとっては大きな節目となる年となった。
それぞれの国、地域におけるAIに関する規制の動きを見ると、生成AIに対する急速な関心の高まりを受けて、各国・地域ではそれまで検討してきたガバナンス制度の見直しが求められている。
進化が速い技術に関する規制の整備においては、各国政府が主導しつつも、AI事業者側の自主的な取組も必要であり、官民両輪で進められているところである。
欧州連合(EU)
域内発のビッグテック企業が無い欧州は、他の地域に先駆けて最も厳しい規制を志向し、2020年からAIの規制に関する議論を続けてきた。
2024年5月21日には、欧州市場でAIシステムを開発・提供・利用する事業者を対象とする、法的拘束力を持つ世界初の包括的なAI規制法と位置付けられるAI法(AI Act)(以下「AI法」という。)が成立した。
AIの規制に関する包括的な法律の成立は主要国・地域で初めてとされており、今後段階的に適用が開始され、2026年頃には本格的に適用される見込みである。
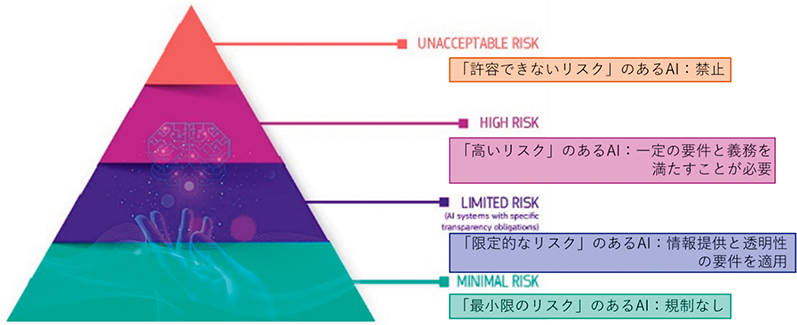
AI法は、リスクに応じて規制内容を変える「リスクベースアプローチ」という方針に基づいている。
規制対象を、①許容できないリスク、②高いリスク、③限定的なリスク、④最小限のリスク、という4段階のリスクレベルのAIアプリケーション及びシステムに分類し、それぞれに対して異なる規制を課すこととしており、上記の規制に違反した事業者には、最も重い違反の場合、最高で3,500万ユーロ(約56億円)の罰金、あるいは年間売上高の7%の制裁金が科される可能性がある。


米国
ビッグテック企業を多く保有する米国は、自国の企業保護に力を入れ、政府による規制よりも民間での自主的な対応を優先し、企業の取組に任せつつ必要の場合に政府が規制をかけるという立場をとってきた。

民間側の取組として2023年7月、AI開発で先行する7社(Google、Meta PlatformsやOpenAI等)がAIの安全な開発のための自主的な取組を約束したこと、更に9月には新たな8社(IBM、Adobe、NVIDIA等)がそれに合意したことを米国政府が発表した。
各社は、自主的なコミットメント(Voluntary Commitments)として、安全性、セキュリティ、信頼性の3つの観点から原則を掲げている。
①システム公開前の安全性確保:各社は、AIシステムをリリースする前に安全性のテストを行う。またAIのリスク管理に関する情報を、産業界、政府、市民社会、学術界と広く共有する。
②セキュリティを確保したシステムの構築:各社は、独自のモデルや公開前のモデルの重要性を保護するために、セキュリティの確保では、サイバーセキュリティ対策やAI開発に係る知的財産の保護等を行う。また、第三者によるAIシステムの脆弱性の発見と報告を促進する。
③国民の信頼の獲得:各社は、AIが生成したコンテンツであることを利用者が知ることができるよう、電子透かしの技術等、堅牢な技術を開発する。また、AIシステムの能力、限界、適切/不適切な使用領域を公表する。
ホワイトハウスは、強制力のある規制が導入されるまで、各社が上記の取組を続けるとしていた
が、その3か月後となる2023年10月30日、バイデン大統領は、「安全・安心・信頼できるAIの
開発と利用に関する大統領令(Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence)」を発表した。
対象とするAIの問題については、従来の倫理的観点から、安全保障問題に範囲を拡充しており、対象となる事業者はビッグテック企業に限らず、バイオテクノロジー企業等、国家の安全保障や経済に影響を及ぼす可能性のあるサービスや製品を取り扱う企業も含まれる。
その内容については、AIに関する新たな安全性評価、公平性と公民権に関するガイダンス、またAIが労働市場に与える影響に関する調査等を義務付けるものであり、AIの安全性とセキュリティのための新しい基準、米国民のプライバシー保護、公平性と公民権の推進等をその主要な構成要素としている。

大統領令の発表に引き続き、同年11月には、ハリス副大統領が、先述の英国AI安全性サミットにて「安全で責任あるAI利用の新イニシアチブ(New U.S. Initiatives to Advance the Safe and Responsible Use of Artificial Intelligence)」を発表し、その中で、大統領令の内容を具体化するべく、「米国AI安全研究所(AI Safety Institute)」(以下「US AISI」という。)を設置するとした。
US AISIは、 国立標準技術研究所(National Institute of Standards and Technology:NIST)内に設置され、危険な機能を評価及び軽減するためのガイドライン、ツール、ベンチマーク、ベスト プラクティスを作成し、AIリスクを特定して軽減するためのレッドチームを含む評価を実施する。
また、人間が作成したコンテンツの認証、AIが生成したコンテンツの電子透かし、有害なアルゴリズムによる差別の特定と軽減や透明性の確保、プライバシー保護の導入等に係る技術的なガイダンスを開発する予定である。
英国のAI安全研究所を含む国際的な同業機関との情報共有や研究協力、更には市民社会、学界、産業界の外部専門家との提携も可能となる。
一方、連邦議会でも連邦レベルでのAI規制に関する法案が議論されている。
2023年6月には、上院が、AIの急速な進歩に連邦議会が対応するための包括的な枠組みである「安全なイノベーション枠組み(SAFE Innovation Framework)」を提唱し、同年12月までに産業界の代表や有識者を招いたテーマ別のフォーラムを9回にわたって開催した。
他方の下院は、2024年2月、AIに関する超党派のタスクフォースを設立すると発表し、AI政策の指針となる原則や政策提言を含む包括的な報告書を作成する予定となっている。
上下両院では、選挙等の個別分野でのAI利用を規制する法案が複数提出されているものの、未だ議会を通過したものは無い。
2024年秋に大統領選挙を控える米国では、生成AIの普及に伴うディープフェイクによる情報操作等の課題に直面し、AIの規制に関する議論が益々活発化するものと予想される。
英国
英国は米国と中国に次いでAI研究が盛んな国とされており、AI分野への民間投資額においても、シンガポールの躍進により2023年に初めて4位に転落したものの、2019年以来、米国・中国に次いで世界3位を保ってきた*25。

現スナク政権は、法的拘束力のあるAI規制には消極的で、安全に配慮しながらAIシステムの開発を促し、経済成長に繋げたいとする考えから、当面はEUのAI法のような厳格な規制を新たに整備せず、既存の枠組みで柔軟に対処する方針を表明してきた。
同方針を踏まえ、英国政府が2023年3月に公表した政策文書「プロイノベーティブな規制手法(A
pro-innovation approach to AI regulation)」が、同国のAI規制の基本的な枠組みに位置付けられている。
同文書では、セキュリティ、透明性、公平性、説明責任、争議可能性の観点から5つの原則が掲げられており、AIガバナンスに取り組むに当たっては、「イノベーション促進型の、柔軟で法規制に縛られない、比例的で信頼できる、順応性があり、明確で且つ協力的な(proinnovation, flexible, non-statutory, proportionate, trustworthy, adaptable, clear and collaborative)」アプローチをとるとしている。
①安全性、セキュリティと堅牢性:AIシステムは、そのライフサイクルを通じて、堅牢、セキュア且つ安全でなければならず、リスクは常に特定、評価、管理されなければならない。
②適切な透明性・説明可能性:AIシステムの開発者・実装者は、関係者に対してAIシステムがいつ、どのように、どのような目的で使用されているかの情報を十分に提供し、関係者に対して、AIシステムの意思決定プロセスの十分な説明を提供しなければならない。
③公平性:AIシステムは、そのライフサイクルを通じて、個人あるいは法人の法的権利を侵害してはならず、個人を不公平に差別したり、不公平な商業的成果を生み出したりするために使われてはならない。
④説明責任とガバナンス:AIシステムの供給と使用について効果的な監視を確保するガバナンス体制が構築されなければならず、AIシステムのライフサイクルを通じて明確な説明責任が伴わなければならない。
⑤争議可能性と是正:AIによる判断や結果が有害であり、又は重大なリスクを伴う場合、それによって影響を受ける者に対して不服を申し立て、是正する機会を提供しなければならない。
当面は既存の法規制の下、各政府機関の連携により、産業界に対して上記原則の実装を促しつつ、将来的には、原則について何らかの義務化を図る可能性があるとしている。
また、2023年11月27日、英国国家サイバーセキュリティセンター(National Cyber Security Centre:NCSC)と米国サイバーセキュリティ・インフラストラクチャー安全保障庁(Cybersecurity and Infrastructure Security Agency:CISA)が中心となり、日本を含む18か国が共同で、AIシステムのセキュリティガイドラインである「セキュアAIシステム開発ガイドライン(Guidelines for secure AI system development)」*28を公表した。
同ガイドラインでは、AIの設計、開発、導入、運用とメンテナンスの各段階において、取り組むべき事項を取りまとめている。
日本
日本は、民主主義や基本的人権等の観点からは欧米と同様の立場である一方、文化や社会規範の差異により、AIに対する社会認識という点では、欧米とは異なる文化圏にある。
これにより、AIガバナンスの方向性として、欧州が法的拘束力の強いハードローを志向しているのに対し、日本は現時点では、AIガバナンスに関する横断的な法規制によるアプローチではなく、民間事業者の自主的な取組を重んじるソフトローアプローチを志向しており、総務省と経済産業省を中心に取組が
行われてきたところである。
総務省のAIネットワーク社会推進会議による「AI開発ガイドライン」が2017年に、「AI利活用ガイドライン」が2019年に公表され、また同年3月に内閣府の統合イノベーション戦略推進会議が決定した、「人間中心のAI社会原則」を基にしたガイドラインが策定された。
続いて2021年7月に経済産業省が公表した「AI原則実践のためのガバナンス・ガイドライン」(2022年1月に改訂)*32では、AI事業者が実施すべき行動目標が実践例と共に示されている。
同ガイドラインは、AIを開発・運用する事業者が参考にし得るよう、環境・リスク分析やシステムデザイン、運用等の項目毎にまとめられている。
2023年5月、政府は「AI戦略会議」を設置し、AIのリスクへの対応、AIの最適な利用に向けた取組、AIの開発力強化に向けた方策等、様々なテーマで議論を行い、「AIに関する暫定的な論点整理」を公表すると共に、各省庁のガイドラインの統合に向けた作業を進めることとされた。
同年9月には、同会議にて生成AIに対するガバナンスも含めて統合された「新AI事業者ガイドラ
イン スケルトン(案)」が示され、そして12月、政府は「AI事業者ガイドライン案」を公表した。
同案では、人権への配慮や偽情報対策を求め、安全性やプライバシー保護等の10原則を掲げ、人
間の意思決定や認知・感情を不当に操作するものは開発させないとしているが、欧米のような一定
の法的拘束力を持つものではない。
同案はその後、一般からの意見の公募を経て、2024年4月19日に「AI事業者ガイドライン(第1.0版)」として公表された。
また、2023年12月のAI戦略会議において、岸田総理大臣は、AIの安全性に対する国際的な関心の高まりを踏まえ、AIの安全性の評価手法の検討等を行う機関として、米国や英国と同様に日本にも「AIセーフティ・インスティテュート(AI Safety Institute)」(以下「AISI」という。)を設立すると発表し、2024年2月14日、経済産業省所管の情報処理推進機構(Informationtechnology Promotion Agency:IPA)に設置された。
AISIは、英国・米国等の同様の機関とも連携しつつ、AIの開発・提供・利用の安全性向上に資する基準・ガイダンス等の検討、AIの安全性評価方法等の調査、AIの安全性に関する技術・事例の調査などを行っていくこととしている。
第6章 第1節:デジタルテクノロジーとのさらなる共生に向けた課題と必要な取組
該当資料:第1 節 デジタルテクノロジーとのさらなる共生に向けた課題と必要な取組
産業競争力の強化/社会課題解決のためのデジタルテクノロジーの活用推進
デジタルテクノロジーは、産業の競争力を強化し、社会課題を解決するために不可欠な要素となっている。
AI開発力の強化に向けた取組
AIの技術発展はロボットや自動運転といった他のテクノロジーの進歩をもたらし、より高度なサービスの提供を可能とする鍵となる。
AIを活用することで生産性の向上、産業競争力の強化や、新たな市場を生み出し、AIが経済成長の原動力となると期待される。
研究開発の面でも、AIを活用して自律駆動による研究プロセスの革新につなげようとする研究領域が生まれるなど分野横断的に研究開発の基盤までを変えようとしている。
文部科学省が2024年3月15日に公表した「令和6年度の戦略的創造研究推進事業の戦略目標等」の分野横断で挑戦する6つの目標の一つに、「自律駆動による研究革新」が挙げられた。自律駆動型の研究アプローチでは、最も時間を要する実験のプロセスにおいてロボット等による物理的な実験の自動化による効率化・スピードアップを図るだけでなく、仮説立案や予測のプロセスにおいて、方程式に書ききれない複雑な事象に対して規則性を見出すなど、人間の認知能力を超えた論理推論をも実現することで、研究活動のパラダイムシフトを起こすことが期待される。自律駆動型の研究アプローチは人の認知限界・認知バイアスを超えて複雑現象の解明や探索領域の開拓が可能であり、科学研究の方法論を革新させる可能性を持つ。
また、安全保障の観点でも、AIはサイバーセキュリティ分野や軍事面での利用が進められている。
このように、私たちの生活・福祉の向上、産業競争力、技術(研究開発)、安全保障など幅広く大きな影響を及ぼすと考えられるAIについて、自国の開発力を整備拡充することは、今後さらに重要となる。
そのため、政府としては、AI開発のインフラというべき計算資源とデータの整備・拡充が重要との認識の下、事業者の取組や研究開発への支援などに着手している。
計算資源については、スーパーコンピュータ「富岳」を活用したLLM開発*3やGPUクラウドサービスの提供に対する支援などが行われている。
東京工業大学、東北大学、富士通、理化学研究所は、「富岳」政策対応枠において、スーパーコンピュータ「富岳」を活用した大規模言語モデル分散並列学習手法の開発に取り組むことを発表した。また、2023年8月より、名古屋大学、サイバーエージェント、Kotoba Technologies Inc.が参画機関に追加された。
また、AIモデルの性能を大きく左右する訓練データについて、高品質なデータを収集、生成、管理し、そのような高品質データを研究機関や企業間で共有する取組が進められている。
情報通信研究機構(NICT)では、従来からの多言語音声翻訳などのAI自然言語処理に関する研究開発を通して蓄積した言語データ構築に関する知見を活かし、AI学習に適した大量・高品質で安全性の高い日本語を中心とする言語データを整備・拡充し、民間企業やアカデミアにアクセスを提供する取組が進められている。
関連資料:総務省・NICTが整備する学習用言語データのアクセス提供について
さらに、基盤モデルの原理解明を通じた、効率が良く精度の高い学習手法、透明性・信頼性を確保する手法等の研究開発力の強化のための支援にも取り組む*5。
関連資料:AI関連の主要な施策について(案)
こうした産官学の連携を通じて、国産LLM(大規模言語モデル)の開発を推進し、国内のニーズに特化したモデルの作成や、日本語や日本文化に最適化されたAIの提供を実現していくことが重要となっている(第4章第1節参照)。
また、開発の進む国産LLMは、東南アジア諸国などの非英語圏における独自言語モデル構築への展開可能性が十分にあると期待されている。
東南アジア諸国においては、短期間でそれぞれの言語モデルを独自に開発することは、データ不足等の要因もあり厳しいと予測されるため、日本語モデルの構築ノウハウを、東南アジア各国における言語に展開していくことは、アジア地域として欧米に対する経済競争力を持つよい機会と捉えられるとされている。
また、欧米のビッグテックによるサービスの日本展開にあたり、国内で開発した日本語モデルを活用してライセンス料を得るという形も考えられる。
従来は、欧米と言語圏が異なることが経済競争においてハンディキャップであったものを、逆手にとれる状況である。
上記において、政府が戦略的に投資していくことで、国産LLMの国際的な存在感を確立することにつながると期待が寄せられている。
適正な市場環境や利用者保護のための透明性向上等に向けた取組
従来、IT業界は「GAFAM」(Google、Amazon、Facebook(現Meta Platforms)、Apple、Microsoft)に代表されるビッグテック企業に牽引されてきたが、AIの進展や普及に伴い、これらビッグテック企業への更なるデータの集中が懸念されている。
デジタル市場のプラットフォームやクラウドサービスにおいて、ビッグテック企業は既に支配的な地位を占めているが、AIの登場により、GAFAMにAI関連企業を加えた「マグニフィセント・セブン」や、「ビッグ4」と呼ばれるテック企業もその支配力を拡大している。
マグニフィセント・セブンと呼ばれるのは、GAFAMに、生成AIに欠かせない画像処理半導体(GPU)のシェア9割近くを持つと言われるNVIDIAと、世界最大級の電気自動車メーカのTeslaを加えた7社である。
また、ビッグ4とは「GOMA」(Google、OpenAI、Microsoft、Anthropic(米スタートアップ))とも呼ばれ、デジタル市場において、既に技術的及びビジネス上の優位性を蓄積している。
上記のようなビッグテック企業の競争優位性が益々高くなっている理由としては、ネットワーク効果や高いスイッチング・コストのほか、AIの開発と運用に莫大なコストがかかることが挙げられる。
例えば、OpenAIの生成AI「ChatGPT」の運用には、1日70万ドル(約1億円)のコストがかかるといわれ、また、Googleの生成AI「Bard」の実行には、Google検索の約10倍のコストがかかるとの試算もある。
また、Microsoft、Google、Amazonが世界のクラウド・コンピューティングシェアの約3分の2を占め、Meta Platformsが独自の強力なデータセンタ・ネットワークを保有している中、AI製品を開発する企業等は、MicrosoftのAzure、GoogleのGoogle Cloud Platform、AmazonのAmazon Web Services(AWS)のいずれかのクラウドサービスやその組み合わせに依存しながら、AI製品を構築する必要がある。
こうした主要なクラウドプラットフォームを使うほどにビッグテック企業の利益となり、その支配力も増していくこととなる。
さらに、AIのプログラム作成には、コンピューティング能力に加え、膨大な量のトレーニングデータも必要である。
これらビッグテック企業は膨大なデータの収集においても競争優位性を持ち、結果として非常に有利な状況にある。
こうしたデジタル市場における支配力を増すビッグテック企業に対し、日本ではこれまで、デジタルプラットフォームにおける取引の透明性と公正性の向上を図るために、2021年2月に「特定デジタルプラットフォームの透明性及び公正性の向上に関する法律」(令和2年法律第38号)が施行された。
同法では、デジタルプラットフォームのうち、特に取引の透明性・公正性を高める必要性の高いプラットフォームを提供する事業者を「特定デジタルプラットフォーム提供者」として指定し、利用者に対する取引条件の開示や変更等の事前通知、運営における公正性確保、苦情処理や情報開示の状況などの運営状況の報告を義務づけている。
さらに、2024年、モバイルOS、アプリストア、ブラウザ、検索サービスといったスマートフォ
ンの利用に特に必要な特定ソフトウェアを提供する事業者が、特定少数の有力な事業者による寡占
状態となっており、様々な競争上の問題が生じているとして、セキュリティやプライバシー等を確
保しつつ、競争を通じて、多様な主体によるイノベーションが活性化し、消費者がそれによって生
まれる多様なサービスを選択でき、その恩恵を享受できるよう、競争環境を整備する必要があると
して、「スマートフォンにおいて利用される特定ソフトウェアに係る競争の促進に関する法律案」
が国会に提出され、6月に成立したところである。
生成AI時代に求められる人材育成
第3章で述べたように、生成AIの登場は社会・経済活動に大きなインパクトを与え、様々な業務領域で変革を起こしている。
「研究開発領域に限らず、ビジネスにおいて生成AI活用による変革を推進するためには、経営層が投資判断などの意思決定を適切に行うための基礎知識が必要」との指摘もあり、「基盤モデルを構築するためにどれだけのデータや計算資源が必要になるか、従来型の情報処理で十分なものと基盤モデルやディープラーニングを必要とするものとの違いなど、テクノロジーを適材適所で使うための知識は、どの業界の経営層も持っておかなければ、怪しい宣伝文句につられて不必要な領域に多額の投資をすることになりかねない」とし、経営層を含めたあらゆるビジネスセクターに対して基礎知識を身につけるための教材が重要になると示唆されている。
経済産業省において2021年2月から開催している「デジタル時代の人材政策に関する検討会」
では、2023年度の主な検討事項として「デジタル人材育成に係る生成AIのインパクト」が議論さ
れてきており、2023年8月「生成AI時代のDX推進に必要な人材・スキルの考え方」を取りまと
めた。
この報告書においては、生成AI時代に必要なリテラシーレベルのスキルとして、
- ①環境変化をいとわず主体的に学び続けるマインド・スタンスや倫理、知識の体系的理解等のデジタルリテラシー、
- ②指示(プロンプト)の習熟、言語化の能力、対話力、
- ③経験を通じて培われる「問いを立てる力」「仮説を立てる力・検証する力」
等が重要になるとされている。
これを受け、経済産業省は、デジタルスキル標準のうち、DXに関わる全てのビジネスパーソンが身につけるべき知識・スキルを定義した「DXリテラシー標準(DSS-L)」(2022年3月策定)について見直しを実施し、生成AIの適切な利用に必要となるマインド・スタンス、及び基本的な仕組みや技術動向、利用方法の理解、付随するリスクなどに関する文言追加を行った。
今後も、生成AIの進展がもたらす新たな課題について、引き続き議論を続けていくこととしている。
安心・安全で信頼できる利用に向けたルール整備・適用と国際協調
AIの進化に伴い、デジタルテクノロジーがもたらすリスク・課題も深刻になることが想定されるため、AIのガバナンスや規制のあり方については、国際的な協調のもとでのルール整備とその遵守が必要不可欠となる。
第4章でも触れたように、我が国では既に、AI事業者ガイドラインが策定され、民間事業者による自主的な取組が浸透し遵守されるよう、本ガイドラインの周知活動を実施しているところである。
このAI事業者ガイドラインの履行とともに、AI戦略会議を中心とし、今後政府全体として制度の在り方についての検討を進めていく予定である*26。
関連資料:AI戦略の課題と対応
また、G7、OECD、GPAI及び国連等の多国間の場における協調と協力の強化も必要である。
2023年5月のG7で立ち上がった広島AIプロセスについては、我が国が議長国として議論を主導しつつG7国間での集中的な議論を行い、同年12月には生成AI等の高度なAIシステムへの対処を目的とした初の国際的政策枠組みである「広島AIプロセス包括的政策枠組み」及びG7の今後の取組について示した「広島AIプロセスを前進させるための作業計画」について合意に達した。
その中では、AIガバナンス枠組み間の相互運用性の重要性が強調されている。
また、2024年のG7議長国イタリアは、広島AIプロセスの継続的な推進を表明しており、2024年3月に採択された「G7産業・技術・デジタル閣僚宣言」では、開発途上国・新興経済国を含む主要なパートナー国や組織における広島AIプロセスの成果の普及、採択、適用を促進するためのアクションが歓迎されたところである。
また、2024年5月にパリで開催されたOECD閣僚理事会で我が国は議長を務め、広島AIプロセスの成果を踏まえ、2019年に採択された「OECD AI原則」の改定に貢献した。
併せて、生成AIに関するサイドイベントにおいて、岸田総理大臣が、49か国・地域が参加する、広島AIプロセスの精神に賛同する国々の自発的な枠組みである「広島AIプロセス フレンズグループ」の立ち上げを表明した。
松本総務大臣は、「AIの国際的なルールづくりを日本が主導することにより、我が国のビジネス環境への信頼性が高まり、日本への投資促進にもつながる。
また、デジタル分野に係るルールについて、日本中心の標準化を目指したい。」と述べ、今後も国際指針等の実践に取り組み、世界中の人々が安全、安心で信頼できるAIを利用できるよう協力を進めていくこととしている。
関連資料:令和6年第5回経済財政諮問会議
コラム:AIやロボットと協働・共生する未来に向けて(コンヴィヴィアルな関係)
AIの未来シナリオ
2023年5月の第2回AI戦略会議等で、東京大学インクルーシブ工学連携研究機構の川原圭博機構長は、AIの未来シナリオを公表している。
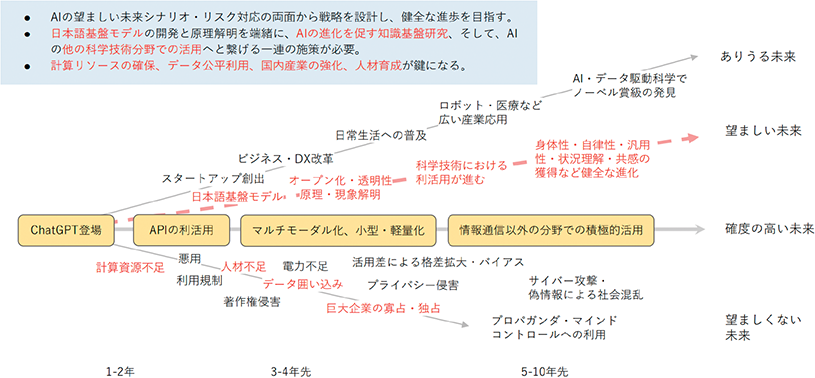
この未来シナリオでは、3-4年先にはマルチモーダル化が実現し、5-10年後の未来において生成AIがロボットに組み込まれるなどして身体性を獲得していくという進展が描かれている。
同時に、AIの悪用については急速に進んでおり、サイバー攻撃や偽情報による社会混乱や巨大企業の寡占・独占による弊害への対策が求められるとしている。
こうした未来シナリオとリスクを踏まえると、我々がAIなどデジタルテクノロジーを活用していくには、
技術だけでなく、倫理や社会的な側面も含めた様々な課題やリスク対応などの総合的な議論が必要である。
近年、生成AIの急速な発展・普及などに伴い、AIの技術やシステムが個人や社会に与える潜在的なリスクや課題(Ethical, Legal and Social Issues:ELSI)を分析し、解決策を模索する取組もより活発になっている。
2019年3月に公表された「人間中心のAI社会原則」では、基本理念として、次の3点を定めている。
- 人間の尊厳が尊重される社会(Dignity)
- 多様な背景を持つ人々が多様な幸せを追求できる社会(Diversity & Inclusion)
- 持続性ある社会(Sustainability)
また、2024年4月に公表された「AI事業者ガイドライン」では、各主体が取り組むべき指針として、「人間中心」を第一に掲げ、「AIが人々の能力を拡張し、多様な人々の多様な幸せ(well-being)の追求が可能となるように行動することが重要である」としている。
また、「AIシステム・サービスの開発・提供・利用において、自動化バイアス等のAIに過度に依存するリスクに注意を払い、必要な対策を講じる」として、自動化バイアス、すなわち人間の判断や意思決定において、自動化されたシステムや技術への過度の信頼や依存が生じるリスクへの対応が必要であるとしている。
AI・ロボットとのコンヴィヴィアル(自立共生的)な関係
このように、未来の社会を築く上で、AIなどのテクノロジーに過度に依存せず、テクノロジーの進歩がも
たらす可能性とリスクをバランスよく見極めながら、人間中心に人々の幸福追求を実現することが重要となっている。
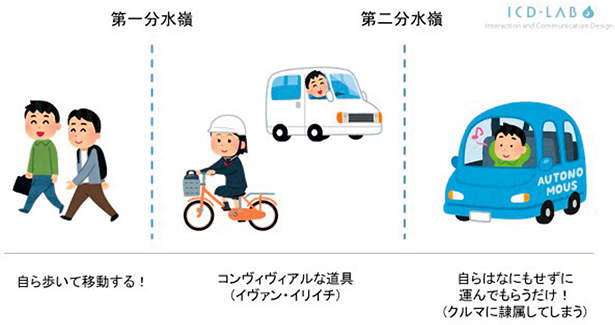
その中で、コンヴィヴィアリティ(自立共生的な関係)という概念が提唱されている。コンヴィヴィアリティとは、オーストリアの思想家イヴァン・イリイチが1973年に刊行した著書「コンヴィヴィアリティのための道具」において提唱した概念である。
イリイチは、テクノロジーが出現して普及しはじめ、人がそれを使いこなすことで人間の自由度が高まる段階を「第一の分水嶺」、次第に人がテクノロジーに隷属し、自由が奪われ始める段階を「第二の分水嶺」とし、この第一と第二の分水嶺のあいだにとどまることが肝要と述べている。
人間と共生する「弱いロボット」の研究を推進している豊橋技術科学大学の岡田美智男教授は、AIやロ
ボットとの関係においても、お互いの主体性を奪わない程度にゆるやかに依存しあうコンヴィヴィアルな関係を志向し、お互いの能力が十分に生かされ、生き生きとした幸せな状態(well-being)を向上させるためのテクノロジーであることが求められるとし、ロボットと人とが和気あいあいと共棲を楽しむような関係を目指す「コンヴィヴィアル・ロボティクス」を提唱している。
例えば、移動におけるコンヴィヴィアルな関係については、歩いて移動することが当たり前だった時代か
ら、自転車が普及することにより人は自らの能力が拡張される感覚を持つようになる(第一の分水嶺)が、自動車、さらに完全自動運転車の実現により自分は能動的に動く必要がなくなり、自分が「荷物」になったような感覚になってしまうと、必ずしも幸せな状態とは呼べない(第二の分水嶺)。
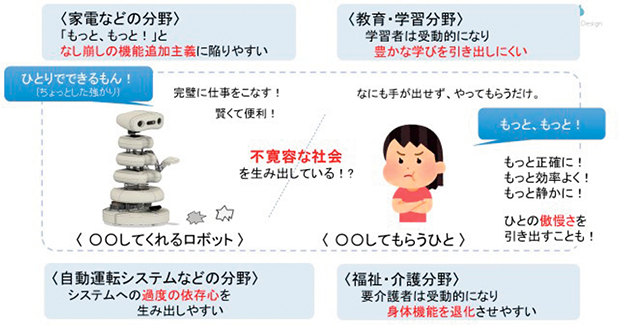
従来の製品・サービスの開発は「足し算」で機能追加を行っていく傾向にあり、これを米国の認知科学者ドナルド・ノーマンは「なし崩しの機能追加主義」と呼んだ。
しかし、機能性を高め、利便性を追求しすぎることは、相手の主体性を奪い、また更なる要求を募らせ提供者側のコスト高にもつながり、消耗戦に陥りやすくなる。
教育・学習の分野においては、サービス享受者が主体性を失い受動的になりすぎると豊かな学びを引き出しにくくなり、福祉・介護分野においては要介護者の身体機能の退化にもつながりかねないこととなる。
しかし、例えば全国の飲食店等で広く受け入れられているネコ型配膳ロボットの例では、客は運ばれてきた料理を自身の手でテーブルに配膳しなければならないという不完全さを受け入れ、ロボットのために道を譲るなど、むしろ生き生きとして協力する姿が見られる。
この例では、テーブルへの配膳機能をつけるための多大なコストをかけることなく、サービス提供側と享受側の垣根を超えて人との共生関係のなかで目的を叶え、ロボット製造者、飲食店、客の3者ともに幸せな状態を生み出すことを自然な形で実現している。


コメント